1 引言
通信辐射源设备由大量的单元器件组成,这些元器件在制造时存在不同程度的误差,加上辐射源内部结构复杂,半导体元器件非线性对调制信号的影响以及外部环境对器件工作参数的影响,使得即使是同一厂家生产的同型号设备,其调制信号也会存在细微的差别[1]。这些调制信号中的细微差别能够反映个体特性,如同人类指纹一样能够起到身份标识的作用,在信号分析理论中被称为细微特征或“指纹”特征。通信辐射源个体识别技术就是通过提取调制信号上的细微特征,与信号特征库中信号进行比对,实现对辐射源设备的锁定,进而对重要设备进行跟踪和有效监视[2]。目前该技术在感知无线电[3],无线网络物理层安全防护[4]等方面有所应用。
受到不同辐射源设备内部器件的差异,调制信号中的非线性产物如谐波,交调干扰,互调干扰以及杂散输出如放大器非线性失真等的影响,实际辐射源信号存在非线性,非平稳的特点[5- 6]。文献[7]指出,可以提取实际通信辐射源的这些非线性动力学参数,作为信号指纹特征进行辐射源识别。Yuan等[8]通过提取信号的归一化排列熵作为指纹特征,来识别同种调制方式的不同电台信号,与一些基于双谱及调制参数的方法对比,具有明显优势。Huang等[9]在此基础上将辐射源看作一个非线性动力系统,通过Hilbert变换得到信号的幅度、相位、频率序列,利用相空间重构提取序列的排列熵作为信号指纹特征,分别在同类型的无线网卡及数字电台间进行指纹提取识别实验,都取得了良好的识别效果,但该方法存在以下问题:实验在理想条件下进行,较少受到信道环境影响,信号质量普遍比较高,容易识别;Hilbert变换在处理非线性非平稳信号时存在局限性,直接用来提取信号的暂态信息存在误差;同型号辐射源个体信号差异较小,从Hilbert变换的结果中提取特征区分能力有限,在辐射源种类增加时,识别性能受到较大的影响。
基于上述考虑,本文将辐射源看作一个非线性动力系统,利用不同设备信号的非线性复杂度差异来实现不同辐射源个体的识别。考虑到通信辐射源设备内部情况复杂,直接从信号中提取特征无法充分表征辐射源间的细微特征,造成分类识别精度不高,采用固有时间尺度分解(Intrinsic Time-scale Decomposition, ITD)对信号进行处理,提出了一种结合ITD与非线性动力学分析的信号细微特征提取算法。对ITD分解后的关键层信号分量进行相空间重构,从中提取排列熵,近似熵,样本熵组成特征向量,从不同尺度上对信号的序列复杂度进行测量,利用支持向量机对特征向量进行训练和分类,通过实验对比,证明了该方法的有效性以及性能优势。
2 基于ITD与非线性分析的特征提取算法
本文算法流程如图1所示,对获取的信号首先进行预处理、分段,采用ITD算法分解信号,利用相关性准则从若干层信号中提取关键层信号;之后对每层信号分量相空间重构,分别提取信号的排列熵、近似熵以及样本熵,从不同尺度对信号的细微特征进行描述;最后,采用支持向量机(support vector machine, SVM)作为分类器,对不同通信辐射源信号进行分类识别。
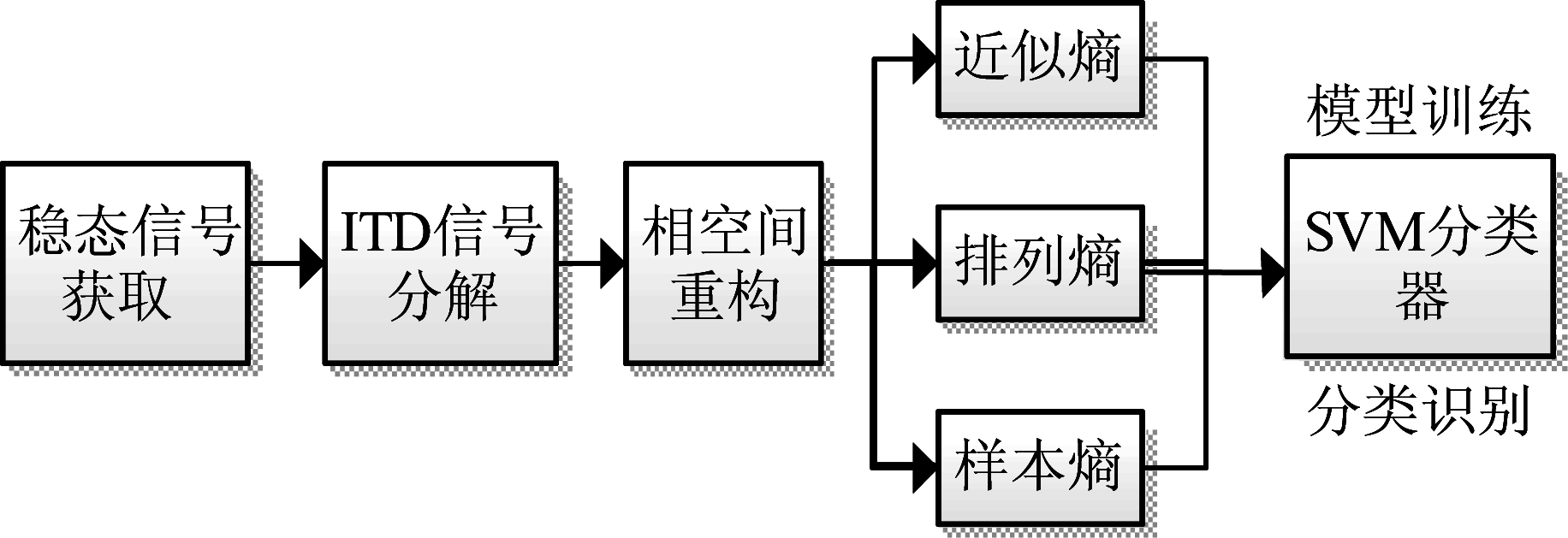
图1 本文算法流程图
Fig.1 Flow chart of proposed algorithm
2.1 基于ITD的信号分解
ITD算法由Mark.G与Ivan.O于2007年提出[10],能够对非线性非平稳信号进行高效准确地分析。该方法可以有效克服传统时频分析方法(傅里叶变换,小波变换等)的缺陷以及经典模态分解(Empirical Mode Decomposition,EMD)[11]处理信号时存在端点效应以及运算效率低的问题,在设备故障诊断以及医学生理信号分析中得到广泛应用。与EMD分解多次筛选模态函数导致信号失真相比,利用ITD分解得到的分量信号能保持原信号局部极值特性,从而提供更加精确的暂态信息,更适用于辐射源信号处理识别[12]。对ITD算法作如下描述:
对于一段实信号Xt(t≥0),定义基线分量提取算子L与旋转分量提取算子, 将原信号分解为两部分:
Xt=LXt+HXt=Lt+Ht
(1)
式(1)中, Lt=LXt表示基线信号,代表信号中的低频部分;Ht=HXt为旋转信号分量,代表信号中的高频部分。设{τk,k=1,2,3,...}为信号Xt的局部极值点,若Xt在某个区间为常数,则选择该区间的右端点作为极值点。为便于表示,用Xk和Lk分别表示极值点X(τk)和L(τk)。假设Lt和Ht在区间[0,τk]有定义,且Xk在区间[0,τk+2]有定义。在相邻的极值区间(τk,τk+1]上可以定义基线信号为:
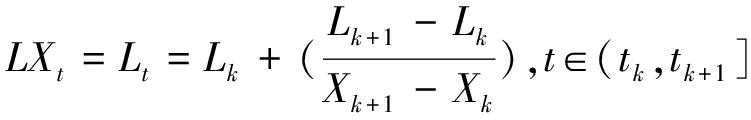
(2)
其中

(3)
0<α<1,通常取α=0.5。这种线性变换构造方法可以保证基线信号在极值点之间保持单调,使得原始信号的固有信息可以传递到基线信号中。信号分解为基线信号与旋转信号后,可将基线信号作为新的输入信号继续分解,直到所得基线信号为单调信号或者达到预设的最大分解层数。该过程可表示为:
Xt=HXt+LXt=HXt+(H+L)LXt=
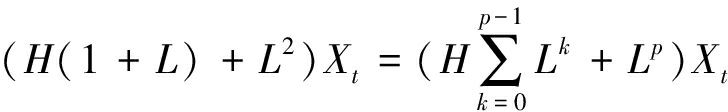
(4)
实信号Xt经过ITD分解得到一系列频率由高到低的旋转信号分量以及基线信号分量,每层信号分量包含的频率成分随信号本身变化而变化,图2给出某一实测辐射源信号片段,经过ITD信号分解得到的一系列旋转信号分量与剩余信号分量的时域波形图,这些信号分量包含了信号深层次的信息,可以从这些信号分量中提取信号的细微特征。
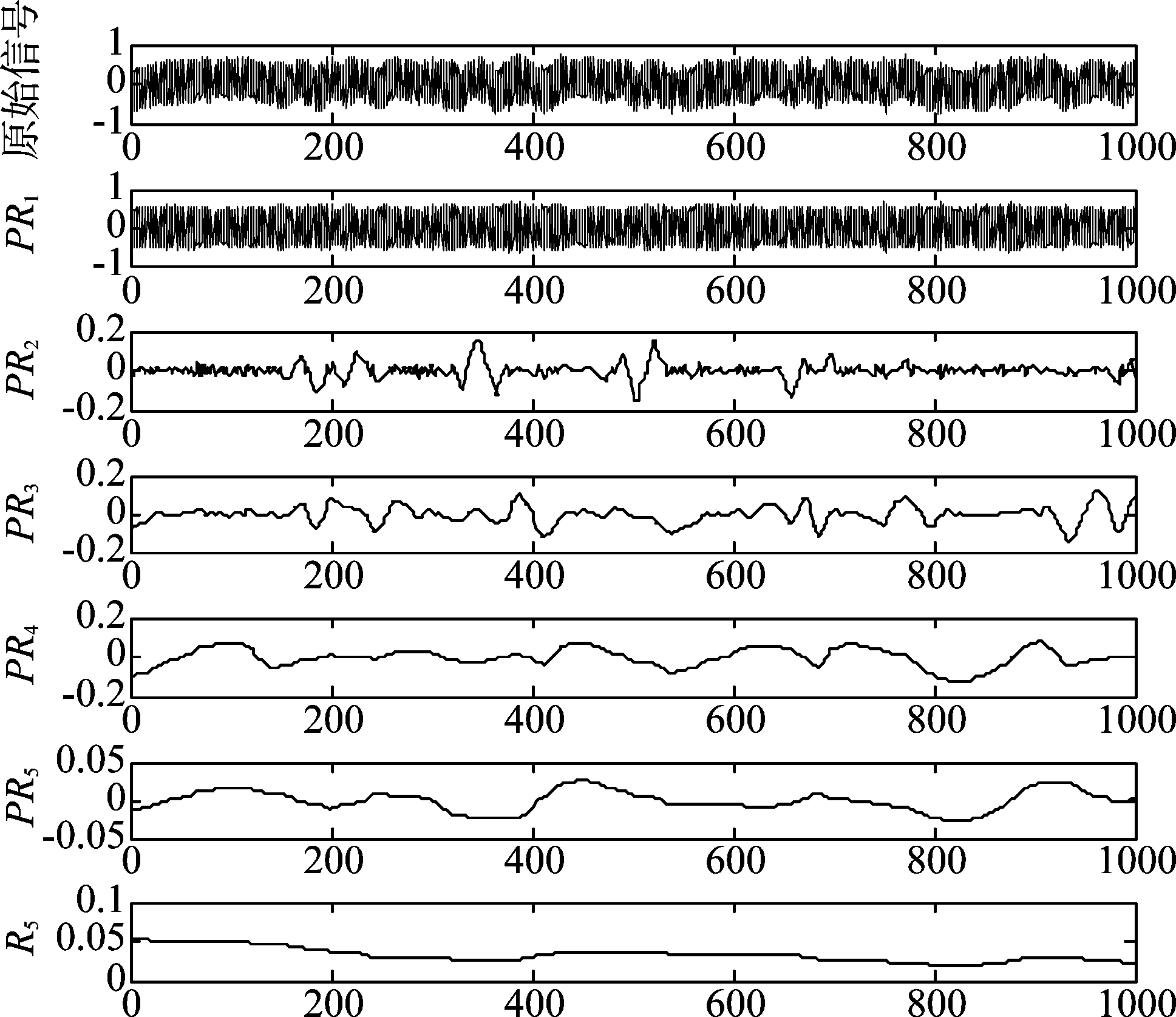
图2 信号经过ITD分解的部分结果
Fig.2 The partial results of ITD
2.2 非线性动力特征分析
辐射源设备如电台、发射机等都是由大量的电子元件(半导体材料)所组成,受到材料结构制造工艺以及外界环境如温度、湿度、噪声等的影响,电子器件的工作状态产生变化,形成各种“噪声”反映在辐射源的调制信号上,难以建模精确评估各种因素对指纹特征的影响。各种因素的影响使得实际辐射源信号具有非线性非平稳的特点,可将辐射源看作一个非线性动力学系统,提取一些非线性动力学参数作为设备“指纹”,进而实现对不同辐射源信号的识别。相空间重构作为分析非线性动力系统的一种有效手段,在许多非线性信号的分析处理中都有应用。信号经过相空间重构,不改变信号特性,因此可从重构的相空间中提取出反应信号状态的特征参数。其对于给定的长度为N的辐射源信号x(n),n=1,2,…,N, 设构建的相空间嵌入维数为m,相空间的时延为τ, 则可将信号通过相空间重构得到相空间矩阵如下:
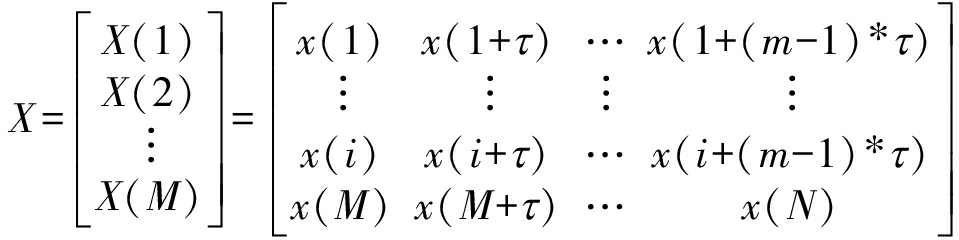
(5)
其中M=N-(m-1)![]() τ为相空间中点的个数,X(i)={x(i),x(i+τ),...,x(i+(m-1)
τ为相空间中点的个数,X(i)={x(i),x(i+τ),...,x(i+(m-1)![]() τ},i=1,2,...,N-(m-1)
τ},i=1,2,...,N-(m-1)![]() τ。本文选定相空间延时τ=1,嵌入维数m的选取根据所提特征不同进行具体设定。
τ。本文选定相空间延时τ=1,嵌入维数m的选取根据所提特征不同进行具体设定。
2.2.1 排列熵特征提取
排列熵[13]由Bandt与Pompe首先提出,是一种对时间序列复杂性度量的非线性动力学参数,具有计算简单,抗噪声能力强的特点,能够准确检测复杂系统的变化。目前,排列熵在气象学数据分析,医学领域脑电、心电等生理信号的分析[14]以及密码学中都已应用。对于N点长的时间序列x(n),将其组成m(m≥2)维相空间重构后的信号X(i)={x(i),x(i+1),...,x(i-m+1)},i=1,2,...,N-m+1。定义一个包含m个元素的顺序集Rm={r1,r2,...,rm}, Rm中所有元素数值都不相同,则Rm中m个元素的大小排列关系共可能有m!种。则对于重构信号X(i),i=1, 2, …, N-m+1, 其中m个元素最多有m!种不同的排列。这就建立起重构信号X(i)与其排列方式的映射关系,统计所有重构信号X(i)各种排列情况出现的频率P1, P2,…, Pm!,按照香农信息熵的定义可以得到排列熵:
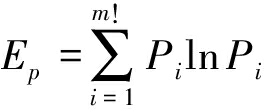
(6)
排列熵Ep反应了N点长时间序列x(n)的随机程度,Ep越小,说明相空间中各向量排列情况出现的越集中,时间序列越规律;Ep越大,说明相空间中各向量排列情况出现的越分散,时间序列越随机。因此可以通过排列熵的大小来反映出不同信号的内在随机性。排列熵的大小与时间序列的嵌入维数m有关,本文将通过实验来确定计算排列熵时,嵌入维数m的选择。
2.2.2 近似熵特征提取
近似熵用来衡量一个时间序列的复杂度,其物理意义为一个时间序列产生新模式概率的大小,概率越大,信号复杂度越大,对应的近似熵也越大。其在分析生物医学信号分析如心率信号,血压信号以及机械设备故障诊断以及信号识别方面有着广泛的应用[15-16]。对N点长的时间序列x(n),组成m(m≥2)维相空间重构信号X(i)={x(i),x(i+1),...,x(i+m-1)}, i=1, 2, …, N-m+1,给定相似容限r,可通过下列方式计算近似熵:
①计算相空间中的点X(i)与X(j)的距离,即:
d[X(i),X(i)]=max1x(i+k)-x(j+k)1
(7)
其中k=0,1,…,m-1, 1≤i, j≤N-m+1,表示两者对应元素最大差值的绝对值。
②对于每个i值,统计向量间距离d小于r的个数与矢量总个数N-m+1的比值记为![]() 定义集合Z={(X(i),X(j)1d[X(i),X(j)]<r,X(i)}则
定义集合Z={(X(i),X(j)1d[X(i),X(j)]<r,X(i)}则
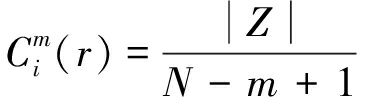
(8)
③对![]() 取对数后取平均值,记作Φm(r)
取对数后取平均值,记作Φm(r)
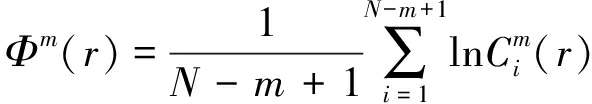
(9)
④对m+1,重复上述过程①~③得到Φm+1(r),进而可得到序列长度为N时序列的近似熵
EA=Φm(r)-Φm+1(r)
(10)
EA的值与m,r的取值有关,根据经验,近似熵的参数作以下设置m=2,r=0.2σ(x),σ(x)表示序列x(n)的标准差。近似熵从统计学角度衡量时间序列的复杂度,序列越复杂,对应的近似熵值就越大。
2.2.3 样本熵特征提取
样本熵作为一种非线性动力学参数,是近似熵的改进算法,广泛应用在机械故障诊断[17]以及生理信号分析中。对N点长的时间序列x(n), 组成m维相空间重构信号X(i)={x(i),x(i+1),...,x(i+m-1)},i=1,2,…,N-m+1,给定相似容限r,可通过下列方式计算样本熵:
①计算相空间中的点X(i)与X(j)的距离,即:
d[X(i),X(i)]=max1x(i+k)-x(j+k)1
(11)
其中k=0,1,…,m-1, 1≤i, j≤N-m+1,表示两者对应元素最大差值的绝对值。
②对于每个i值,统计向量间距离d小于r的个数与矢量总个数N-m+1的比值记为![]() 定义集合T={(X(i),X(j)1d[X(i),X(j)]<r,X(i)}则:
定义集合T={(X(i),X(j)1d[X(i),X(j)]<r,X(i)}则:
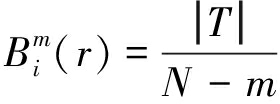
(12)
③求![]() 的平均值,记作Bm(r):
的平均值,记作Bm(r):
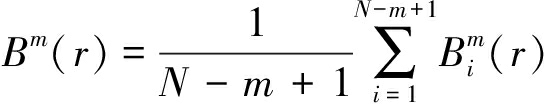
(13)
④增加嵌入维数至m+1,重复上述①~③步骤,可计算得到Bm+1(r)。
⑤则可以计算当样本序列长度为N时的样本熵为:
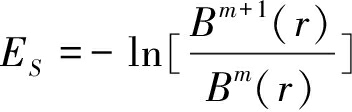
(14)
同样,参数m,r的值对样本熵的计算非常重要,这里取m=2,r=0.2σ(x),σ(x)表示序列x(n)的标准差。待分析的信号存在非线性,非平稳的特点,线性信号分析方法提取的特征将无法准确反映信号特性。利用非线性动力学分析的方法,提取信号的排列熵,近似熵以及样本熵组成特征向量,作为信号的指纹特征,来对不同信号进行描述。
2.3 分类识别
对信号经过一系列计算,提取指纹特征,最终利用分类器实现对辐射源信号的分类识别。SVM是一种常见的分类器,它以统计学习为理论基础,在解决小样本,高维数的分类问题中表现出卓越的性能,因此选用SVM作为分类器。SVM在解决非线性问题时,通过引入核函数,将线性不可分的问题转换为高维空间中线性可分的问题,本文选取高斯径向基函数作为核函数,最佳核参数c与g的选取,则是通过一种交叉验证的方式来获得。交叉搜索通过将核参数c与g在一定变化范围内取值,最终选取使得验证集分类识别率最高的一组c和g作为最佳核参数值。
2.4 算法总结
本文采用调制方式相同,参数相同的6类某部实测舰船通信信号进行分类识别实验,通过预处理,去除信号噪声段,将每类信号几个短的信号段进行拼接。算法涉及到的参数将在实验部分进行讨论,算法步骤如下所示:
(1)每类信号按照每1000点为一个信号样本进行划分,根据后文中的讨论,对每个信号样本利用ITD算法进行3层分解,每个信号样本得到PR1,PR2,PR3与R3共4个信号分量。
(2)将每层信号进行m维相空间重构计算信号非线性动力学特征,对于近似熵EA与样本熵ES,选定m=2计算其数值;对于排列熵Ep, 通过后面实验选定m=5来计算排列熵。对于每层信号分量,可以提取近似熵EA、样本熵ES、以及排列熵Ep三维熵特征,一共可得到12维特征组成特征向量进行信号识别。
(3)每类信号随机选取200个训练样本,100个测试样本,首先对特征进行归一化处理,之后采用SVM进行分类器训练,选用高斯径向基函数作为核函数,利用交叉搜索的方式寻找最优惩罚参数c与核函数参数g,进行分类识别实验,重复100次实验计算平均值作为信号最终识别率。
3 实验分析
3.1 实验信号
为了验证本文所提算法的性能,选取6类实测舰船通信信号作为实验信号,进行细微特征提取与识别实验。这6类舰船通信信号实验数据来自某实地观测站,信号的采样频率为1 MHz,观测信号的中心频率约为294.075 kHz。仅利用本文所提方法提取信号细微特征,来对6类实测舰船通信信号进行分类识别实验。考虑到每段实测舰船通信信号的信号段持续时间短,为了满足实验需求,在信号预处理阶段,将每类舰船通信信号的有效信号段归一化处理,之后将其进行拼接,组成每类样本50万点的实验数据,为便于进行实验对6类实测舰船通信信号编号为M1~M6。这6类实验信号图3所示。

图3 6类实测舰船通信信号
Fig.3 Six measured ship communication signals
图3中,6类信号实测舰船通信信号的调制方式相同,从时域上观察,不同类别信号的波形相似,不同信号间差异较小,这给信号的识别增加了难度。在按照本文所提算法进行细微特征提取之前,需要对该算法涉及的实验参数进行讨论确定。涉及到的实验参数包括信号ITD信号最大分解的层数L,提取排列熵的嵌入维数m,信号样本的长度N。下面对这些参数进行一一讨论确定。
3.2 ITD分解最大层数L
对于调制方式相同的通信信号,其时域波形相似程度高,若直接利用非线性动力学分析方法提取信号特征,难以有效区分不同类别的信号。本文算法考虑将实验信号进行ITD分解,如图4(a)、(b)为选取M1和M2信号中选取的两段信号样本进行ITD分解的结果,可以发现辐射源个体的信号在某些分量上存在较大差异,这给信号细微特征分析提供了基础。对这些信号分量进行非线性动力学分析,提取信号特征,将能大大提高信号识别的准确率。
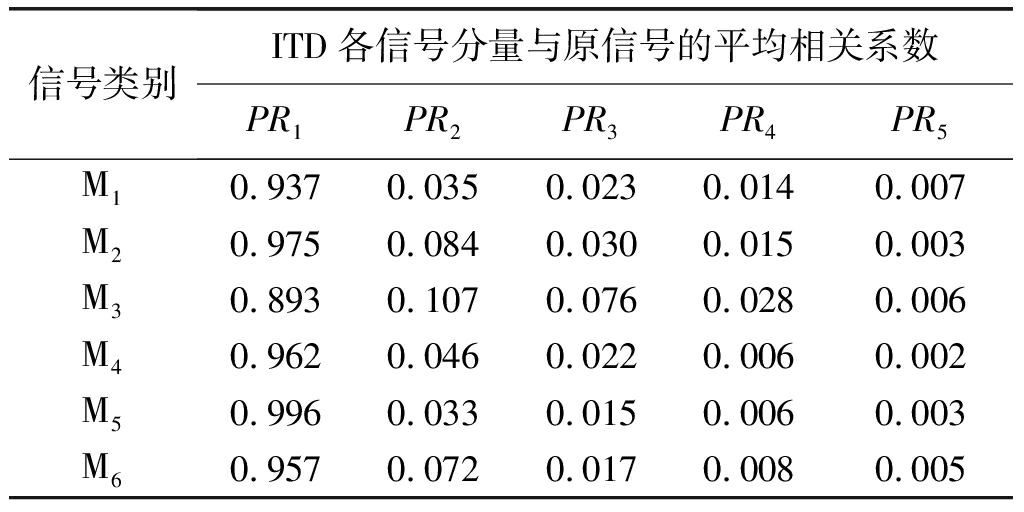
将每类舰船通信信号按照每1000点分为一段,作为一个信号样本,进行ITD信号分解以及细微特征提取。信号片段经过ITD分解,得到一系列频率和幅度都逐渐降低的信号分量,若利用所有信号分量进行细微特征提取,则会增加信号特征提取以及分类器训练的复杂度,影响算法的执行效率。对此,根据信号能量主要集中在前若干个信号分量的特点,计算前5层分解后旋转分量信号与原始信号之间的相关性,从中选取与原始信号相关程度高的信号分量进行细微特征提取。实验从6类实测舰船通信信号中每类选取100个信号样本,计算其ITD分解后前五层信号分量与原始信号分量相关系数的平均值,如下表1所示。
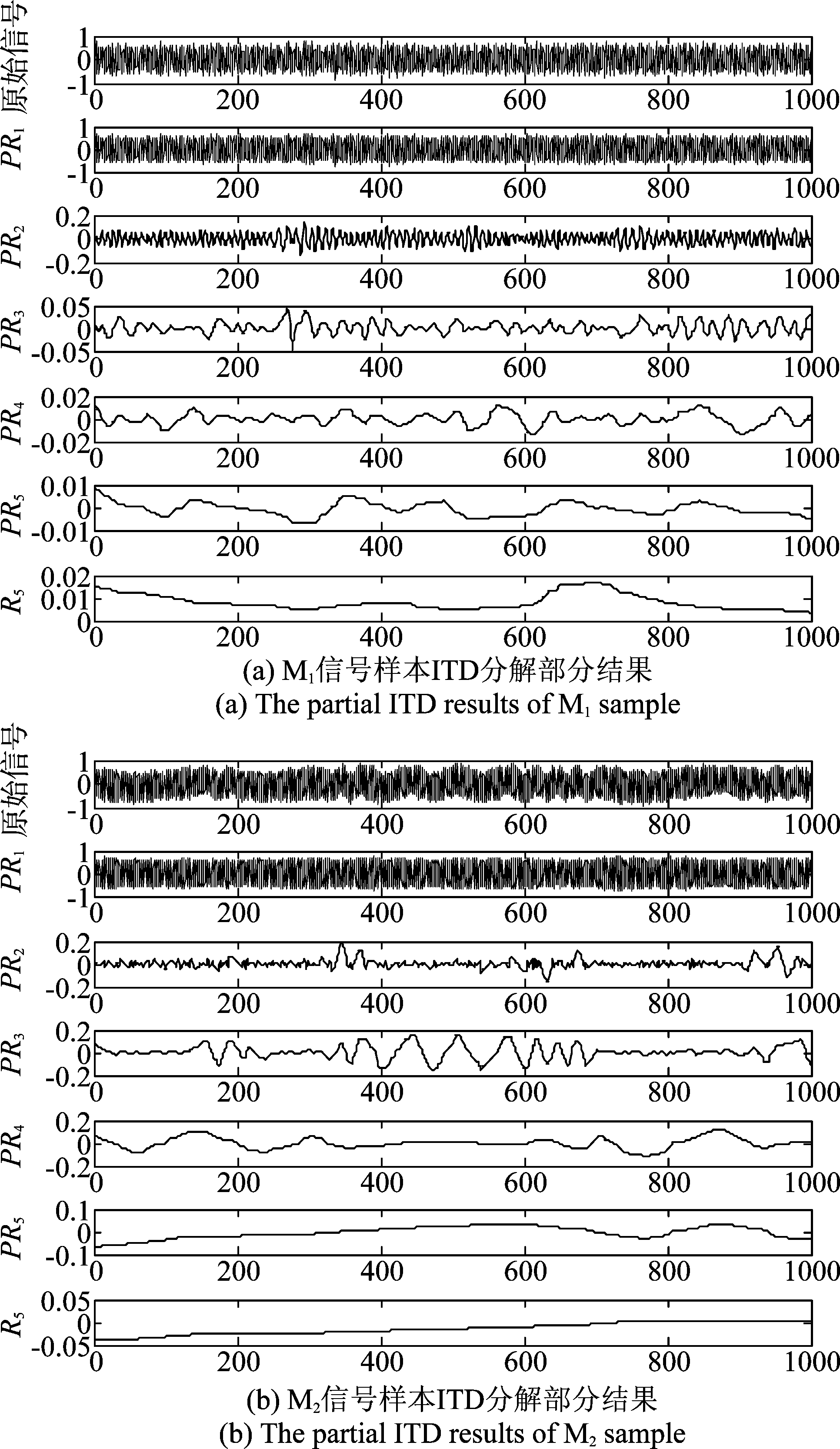
图4 不同种类信号ITD分解结果对比
Fig.4 The comparison of ITD results among different signals
表1 各层信号分量的相关系数
Tab.1 The correlation coefficients of each signal components
信号类别ITD各信号分量与原信号的平均相关系数PR1PR2PR3PR4PR5M10.9370.0350.0230.0140.007M20.9750.0840.0300.0150.003M30.8930.1070.0760.0280.006M40.9620.0460.0220.0060.002M50.9960.0330.0150.0060.003M60.9570.0720.0170.0080.005
相关系数越大,说明该层信号分量与原始信号间相关程度越高,从表1中可以发现,PR1层信号与原信号的相关性最强,分解后信号的能量大部分集中在该层,这点也可从图2各层分解信号中得到证实,综合考虑各层信号相关性以及算法执行效率问题,设定信号最大分解层数L=3,这样对每一个样本信号,经过ITD信号分解后,一共可以得到PR1,PR2,PR3三层旋转信号分量以及剩余信号分量R3,共4层信号分量用于细微特征提取。这种方式相比于直接选取前4层旋转信号分量的方式,能够更充分利用信号信息。
3.3 排列熵嵌入维数m
在利用ITD对信号进行分解得到4层分量信号后,本文所提方法从各分量信号中提取非线性动力学参数作为信号的细微特征,其中提取近似熵与样本熵时,嵌入维数的设置比较固定,参照经验值设定即可。计算排列熵时,嵌入维数m的确定与信号的长度N以及信号自身特点有关,嵌入维数m太小,计算得到排列熵区分能力很差,对于一个N点长的信号样本,嵌入维数m必须满足2≤m,且m!≤N,在满足此条件基础上,一般m越大,利用的数据点前后关联信息越多,排列熵的区分能力越强。取每段信号样本长度N=1000,则嵌入维数m的可能取值为2,3,4,5,6。选取M1~M4这4类实测舰船通信信号,每类500个样本,在嵌入维数m=3,4,5,6的情况下,计算信号样本各层信号分量的排列熵。计算平均Fisher可分离度来衡量不同嵌入维数m下,不同信号的区分程度,作为确定嵌入维数的依据。
设![]() 为第k类信号的第i个信号样本计算得到的l层信号的排列熵,其中k=1,2,3,4分别对应实测舰船通信信号M1,M2,M3,M4,i=1, 2…500。l=1, 2, 3, 4分别对应信号样本ITD分解得到的PR1,PR2,PR3与R4层信号分量。设 k1、k2为4类信号样本中的两类,利用Fisher可分离度来对两类信号l层信号排列熵的可分性进行度量:
为第k类信号的第i个信号样本计算得到的l层信号的排列熵,其中k=1,2,3,4分别对应实测舰船通信信号M1,M2,M3,M4,i=1, 2…500。l=1, 2, 3, 4分别对应信号样本ITD分解得到的PR1,PR2,PR3与R4层信号分量。设 k1、k2为4类信号样本中的两类,利用Fisher可分离度来对两类信号l层信号排列熵的可分性进行度量:

(15)
上式中![]() 与
与![]() 分别表示k1类与k2类信号所有样本l层排列熵的均值,
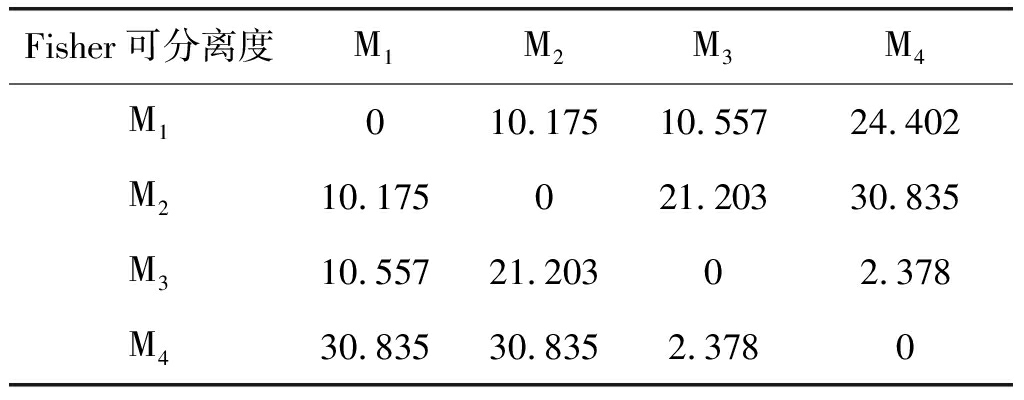
分别表示k1类与k2类信号所有样本l层排列熵的均值,![]() 表示其方差。可以用各层信号Fisher可分离度的均值来对k1、k2两类信号的可分性进行度量J=mean(J(l)),l=1,2,3,4。计算4类实测舰船信号两两间的可分性J(k1,k2),可以得到Fisher分离度矩阵,在嵌入维数m=3,4,5,6下分别计算四类信号的Fisher可分离矩阵,如下表2~表5所示。
表示其方差。可以用各层信号Fisher可分离度的均值来对k1、k2两类信号的可分性进行度量J=mean(J(l)),l=1,2,3,4。计算4类实测舰船信号两两间的可分性J(k1,k2),可以得到Fisher分离度矩阵,在嵌入维数m=3,4,5,6下分别计算四类信号的Fisher可分离矩阵,如下表2~表5所示。
表2 嵌入维数m=3时的Fisher可分性矩阵
Tab.2 The Fisher separation matrix when m=3
Fisher可分离度M1M2M3M4M1010.17510.55724.402M210.175021.20330.835M310.55721.20302.378M430.83530.8352.3780
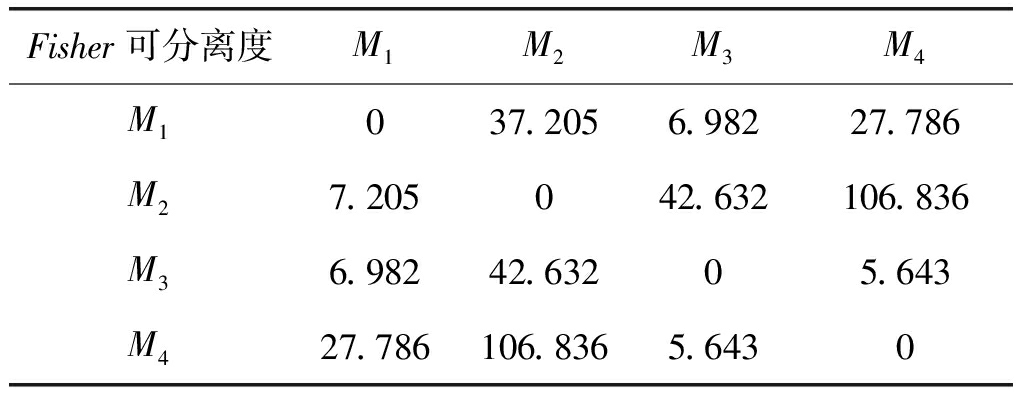
表3 嵌入维数m=4时的Fisher可分性矩阵
Tab.3 The Fisher separation matrix when m=4
Fisher可分离度M1M2M3M4M1037.2056.98227.786M27.205042.632106.836M36.98242.63205.643M427.786106.8365.6430
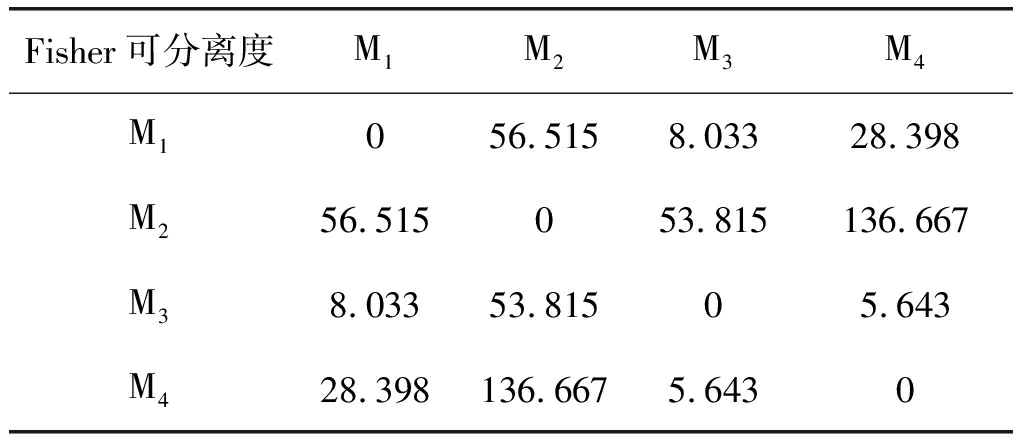
表4 嵌入维数m=5时的Fisher可分性矩阵
Tab.4 The Fisher separation matrix when m=5
Fisher可分离度M1M2M3M4M1056.5158.03328.398M256.515053.815136.667M38.03353.81505.643M428.398136.6675.6430
表5 嵌入维数m=6时的Fisher可分性矩阵
Tab.5 The Fisher separation matrix when m=6
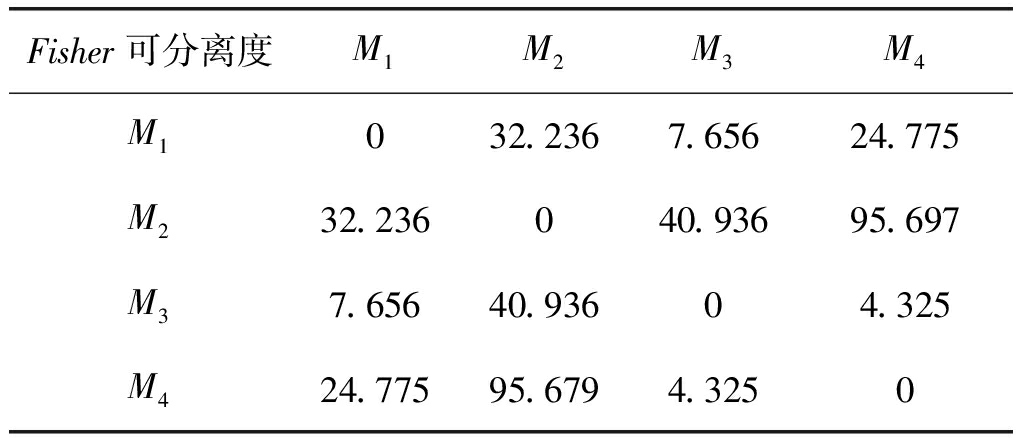
Fisher可分离度 M1M2M3M4M1032.2367.65624.775M232.236040.93695.697M37.65640.93604.325M424.77595.6794.3250
信号间可分离度J(k1,k2)从某种程度上反映了两类信号分类识别的难易程度,对比不同嵌入维数m下,四种信号的Fisher可分性矩阵,综合考虑信号可分离度以及计算复杂度,选定嵌入维数m=5来提取各层信号的排列熵。
3.4 信号长度N的确定
本文所提方法将信号看作一个非线性动力学系统,提取信号的一些非线性动力学参数作为信号细微特征进行识别。这些非线性动力学参数从不同角度反映了信号的复杂程度;值得注意的是,信号样本长度N影响参数的稳定性,在一定范围内,信号样本长度N越长,所提系统参数越稳定,更有利于信号识别。下面通过实验来确定适当的样本信号长度N。
本实验选用所有6类实测舰船信号M1~M6,对每类信号50万点的数据按照信号长度N=500,600,…,1000进行分段。对不同长度信号样本进行如下处理:对信号样本进行ITD分解,得到4层信号分量;对每层信号分量提取排列熵,近似熵以及样本熵三维特征;将所得12维特征组成特征向量。为了进行充分的实验,确定合适的信号样本长度N,每次实验选取K=3,4,5,6种信号进行识别实验,K=4时选用信号M1~M4;K=5时选用M1~M5;K=6时,选用信号M1~M6。在分类实验中,从信号样本中随机选取200段信号作为训练样本,从剩余信号中随机100段信号作为测试样本,采用支持向量机作为分类器,重复100次实验,取100次实验的平均识别率作为最终识别结果。不同信号长度下,本文所提方法的正确识别结果如表6所示。
表6 不同信号长度下,所提方法的正确识别率
Tab.6 The identification accuracy of proposed method with different signal length %
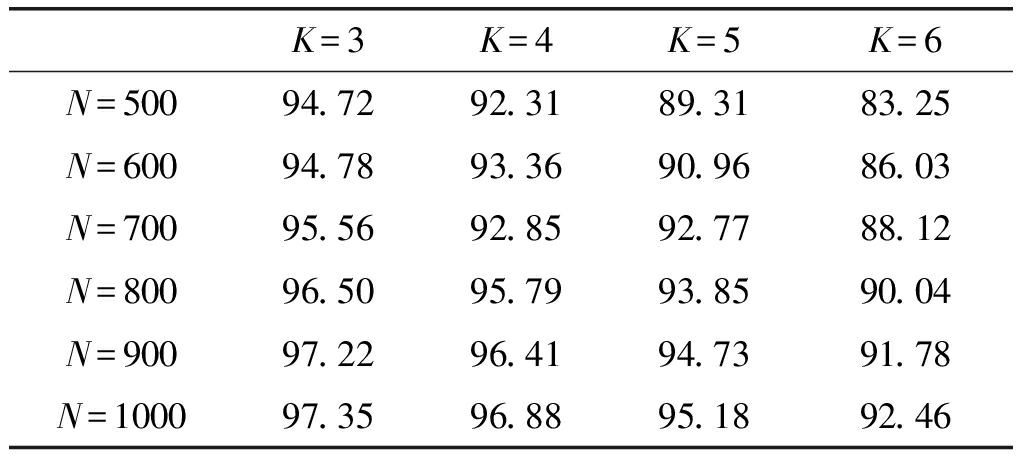
K=3K=4K=5K=6N=50094.7292.3189.3183.25N=60094.7893.3690.9686.03N=70095.5692.8592.7788.12N=80096.5095.7993.8590.04N=90097.2296.4194.7391.78N=100097.3596.8895.1892.46
从表6中可以发现,信号样本长度N会对信号的识别率有一定的影响。总体来讲,信号样本的长度N越长,信号间的分类效果越好。在K=3时,信号样本长度N从500增加到1000,识别正确率提升了3%左右,而K=6时,相同情况下识别正确率提升了9%左右。随着信号识别种类K的增加,信号样本的长度N越长,信号识别率的提升越显著。这是因为相同实验条件下,信号样本长度N越长,从信号中提取的特征参数越稳定,反应出的信号特征区分性就越好。继续增加信号样本长度N进行实验,提取特征计算耗时增加,但识别率的提升不够明显,在此不再列举实验结果。因此在对这6类实测舰船通信信号识别时,设定信号样本的长度N=1000。
3.5 实验结果
通过一系列分析实验,最终确定了本文算法涉及到的一些参数的取值,为进一步对本文算法性能进行评估,选取一些信号细微特征提取方法进行对比实验。分形是对事物自相似性的一种数学描述,目前在辐射源识别领域,常用分形维数中的盒维数与信息维数对信号的细微特征进行描述[18]。对信号样本进行ITD分解后,提取每层信号的盒维数以及信息维数共8维特征,进行对比识别实验,称之为对比方法1。直接提取原始信号样本的排列熵,近似熵以及样本熵3维特征进行对比实验,称之为对比方法2。此外,采用文献[9]中对信号Hilbert变换后,提取排列熵的方法,对实测舰船信号进行分类识别,称之为对比方法3。实验参数参照前文设置,分别在K=3,4,5,6时,在相同实验条件下进行分类识别实验,比较这4种方法的正确识别率如下图5所示。
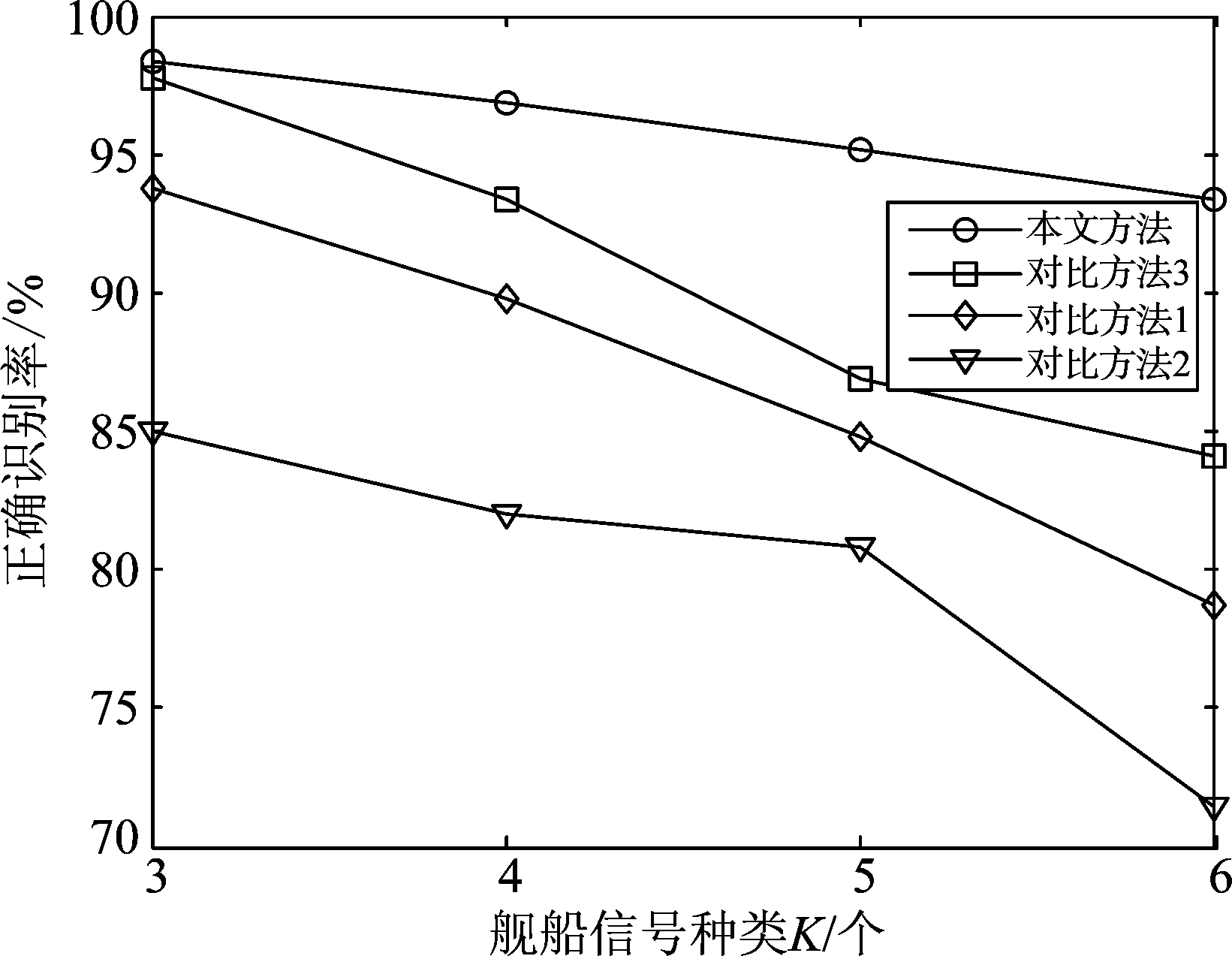
图5 不同方法的识别率对比
Fig.5 Comparison of accuracy among different approaches
图5识别率曲线可以发现,对于实测舰船信号,信号种类K增加,不同方法的识别率都有不同程度的下降,但每种情况下,本文方法识别率最高且随着K增加性能下降的最少。本文方法与对比方法1相比,两种都是从ITD分解后的分量信号中提取特征,实验结果表明,相比于分形维数,非线性特征熵在表征信号指纹特性上具有更高的可分性。相比于对比方法2,同样提取非线性特征熵作为信号分类特征,从ITD分量信号中获取的方式,能够在多个尺度挖掘信号的个体特征,不仅增加了特征的维度,更提升了特征的分类效果。与对比方法3相比,两种方法在信号种类较少时,识别性能差别不明显,随着K增加,两种方法的稳定性有了明显的差异,产生这种情况的原因在于,实测舰船信号受到接收条件的影响,存在非线性非平稳特点,Hilbert变换已不适用;利用Hilbert变换直接从原信号中提取幅度,相位,频率序列的排列熵作为特征,受到多种因素影响,原信号指纹特征不易获取,而通过ITD分解的方式能够挖掘出信号深层而丰富的指纹特性,因此分类性能更好。
4 结论
本文结合混沌系统分析的相关知识,从ITD分解后的分量信号中提取非线性动力学参数作为特征用于信号的细微特征识别。利用6类实测舰船通信信号通过一系列实验,确定了所提方法的最佳实验参数。通过一系列对比实验可以发现:与常用来描述信号不规则程度的分形维数相比,通信信号的非线性动力学参数具有更强的抗干扰能力,同类信号的特征参数较稳定,不同舰船通信信号的特征参数差异明显,具有更强的分类性能。由于实测舰船信号差异较小,直接从原始信号提取非线性动力学特征无法充分反映辐射源内部的细微差异。对信号进行ITD分解后,从关键层信号中提取非线性动力学特征,可以挖掘信号深层次的信息,提升了分类识别的效果。由于Hilbert变换存在局限性,实测舰船通信信号存在非线性非平稳的特点,因此对信号ITD分解的处理相较于Hilbert变换,更能充分挖掘信号的细微特征。
在下一步的工作中,尝试提取一些其他类型的分线性动力学参数,作为信号的细微特征用于辐射源识别中,此外,利用特征选择的相关方法,从所提特征中选取稳定可靠的参数,用于通信辐射源个体识别的工程实践中。
参考文献
[1] Langley L E. Specific Emitter Identification (SEI) and Classical Parameter Fusion Technology[C]∥Wescon'93. Conference Record, San Francisco, California, IEEE, 1993:377-381.
[2] 胡建树. 短波电台个体特征识别[D]. 广州: 华南理工大学,2015.
Hu Jianshu. Identification of Individual HF Transmitters[D]. Guangzhou: South China University of Technology, 2015. (in Chinese)
[3] Kim K, Spooner C M, Akbar I, et al. Specific Emitter Identification for Cognitive Radio with Application to IEEE 802.11[C]∥Global Telecommunications Conference, New Orleans, Louisiana, IEEE GLOBECOM, 2008:1-5.
[4] Ramsey B W, Mullins B E, Temple M A, et al. Wireless Intrusion Detection and Device Fingerprinting through Preamble Manipulation[J]. IEEE Transactions on Dependable & Secure Computing, 2015, 12(5): 585-596.
[5] Liu C, Xiao H, Wu Q, et al. Linear RF Power Amplifier Design for TDMA Signals: a Spectrum Analysis Approach[J]. International Journal of Electronics, 2003, 89(2):135-146.
[6] Cobb W E, Laspe E D, Baldwin R O, et al. Intrinsic Physical-Layer Authentication of Integrated Circuits[J]. IEEE Transactions on Information Forensics & Security, 2012, 7(1):14-24.
[7] Carroll T L. A Nonlinear Dynamics Method for Signal Identification[J]. Chaos: An Interdisciplinary Journal of Nonlinear Science, 2007, 17(2):023109.
[8] Yuan Y, Huang Z, Wang F, et al. Radio Specific Emitter Identification Based on Nonlinear Characteristics of Signal[C]∥IEEE International Black Sea Conference on Communications and Networking. IEEE, 2015:77- 81.
[9] Huang G, Yuan Y, Wang X, et al. Specific Emitter Identification for Communications Transmitter Using Multi-measurements[J]. Wireless Personal Communications, 2016:1-20.
[10] Mark G F, Ivan O. Intrinsic Time-scale Decomposition: Time-frequency-energy Analysis and Real-time Filtering of Non-stationary Signals[J]. Proceedings Mathematical Physical & Engineering Sciences, 2007, 463(2078):321-342.
[11] Huang N, Shen Z, Long S R. The Empirical Mode Decomposition and Hilbert Spectrum for Nonlinear and Non-stationary Time Series Analysis[J]. Proceedings of the Royal Society of London, 1998, 454:903-995.
[12] 桂云川, 杨俊安, 吕季杰. 基于固有时间尺度分解模型的通信辐射源特征提取算法[J]. 计算机应用研究, 2017(4):1172-1175.
Gui Yunchuan, Yang Junan, Lv Jijie. Feature Extraction Algorithm Based on Intrinsic Time-scale Decomposition Model for Communication Transmitter[J]. Application Research of Computers, 2017(4):1172-1175. (in Chinese)
[13] Bandt C, Pompe B. Permutation entropy: A Natural Complexity Measure for Time Series[J]. Physical Review Letters, 2002, 88(17):1595-1602.
[14] 陈振宇, 黄晓霞. 基于多尺度排列熵的精神分裂症MEG信号分析[J]. 中国生物医学工程学报, 2016, 35(6):665- 670.
Chen Zhenyu,Huang Xiaoxia. Magnetoencephalography Analysis of Schizophrenia Using Multi-scale Permutation Entropy[J]. Chinese Journal of Biomedical Engineering, 2016, 35(6):665- 670. (in Chinese)
[15] 符玲, 何正友, 麦瑞坤,等. 近似熵算法在电力系统故障信号分析中的应用[J]. 中国电机工程学报, 2008, 28(28):68-73.
Fu Ling,He Zhengyou,Mai Ruikun,et al. Application of Approximate Entropy to Fault Signal Analysis in Electric Power System[J]. Proceedings of the Chinese Society for Electronical Engineering,2008,28(28):68-73. (in Chinese)
[16] 谢阳,王世练,张尓扬,等.基于差分近似熵和EMD的辐射源个体识别技术研究[J]. 计算机工程与应用.2016, 52(S1):541-547.
Xie Yang, Wang Shilian, Zhang Eryang, et al. Specific Emitter Identification Based on Difference Approximate Entropy and EMD[J]. Computer Engineering and Applications, 2016, 52(S1):541-547. (in Chinese)
[17] 赵志宏,杨绍普.一种基于样本熵的轴承故障诊断方法[J]. 振动与冲击,2012, 31(6):134-140.
Zhao Zhihong, Yang Shaopu. Sample Entropy-based Roller Bearing Fault Diagnosis Method[J]. Journal of Vibration and Shock, 2012, 31(6):134-140. (in Chinese)
[18] Dudczyk J, Kawalec A. Fractal Features of Specific Emitter Identification[J]. Optical and Acoustical Methods in Science and Technology, 2013,124:406- 409.


