1 引言
随着社会上暴恐袭击、人群拥挤踩踏等安全问题的发生,智能视频监控技术的发展显得愈加重要,考虑到中、高密度的人群往往更容易发生突发状况,且现实中公共场所存在大量的视频监控,故针对人群的异常行为检测越来越受到学者、管理者的重视,具有较高的研究与应用价值,视频中人群异常行为检测技术已成为近年来智能视频监控领域的一个研究热点。
人群异常行为检测首要解决的问题即是如何界定人群中的异常行为和正常行为。异常行为的定义通常具有很大的人为主观性,特点为发生概率小,且正常人能够明确地发觉,通常易对他人、公共场合等造成不利影响或预示着危险事故的发生[1]。根据这一特点,研究者重视的人群中异常行为有行人围观拥堵道路、可疑人往人群丢包裹[2]、广场及室内场合的恐慌奔跑、车辆闯入人行道等行为[3],此外,行人徘徊、摔倒、多人打架斗殴[4]等异常行为检测也备受关注。
近年来,研究者已经在人群异常行为检测领域提出许多有效方法。总体上,根据表征人群运动行为特征提取方法的不同,可将异常行为检测大致分为2类:①基于低级视觉特征的算法,如文献[5]通过对每一训练帧提取最大光流映射直方图特征,构建过完备字典,设定稀疏重构阈值判断检测帧是否异常。可有效检测全局异常行为,但无法定位异常,算法耗时多。文献[6]提出一种基于混合核动态纹理的视频异常行为检测算法,对视频块的表观和时域动态变化进行建模,从时间上和空间上分别检测异常行为和定位物体,但当行人相互之间遮挡时,外观发生变化,易造成误检。②基于高级视觉特征的算法,如文献[7]通过检测并跟踪视频帧中特征点获得轨迹片段,计算轨迹段直方图作为视频分块高级描述子,使用LDA生成模型划分视频帧是否存在异常行为。算法提取了更长期运动轨迹的运动信息,但特征点检测性能与跟踪稳定性对特征描述的有效性存在很大影响。Chaker则认为可从人群的能量变化判定视频中异常行为,对人群能量建立马尔科夫模型,对检测帧推断异常行为的发生[8],但不能用于长期的推断。
为了充分挖掘表征人群运动模式的高级视觉信息,并更有效地从异常帧中定位异常运动的人或物体。本文提出了一种基于运动前景效应图特征的人群异常行为检测算法,算法先通过自适应混合高斯背景分割算法提取视频帧序列的前景区域,将每一视频帧在空间上分块获得运动前景块,并计算所有运动前景块给周围块带来的运动效应,可获得每帧相应的效应图,取时间上连续多帧的空间子块作为空时块,提取每个空时块的效应图特征。最后通过一种改进的优化初始聚类中心的K-means聚类算法对训练帧序列进行聚类训练,空时块可快速地匹配最近的聚类中心,设定固定阈值可判定其异常与否。
2 运动前景提取
分析判断视频中异常行为的一个行之有效的方法即是分析运动行人或物体的运动信息[4-7,9],表现异常行为的运动行人或物体往往表现出异常的运动状态。故重点分析视频中的运动前景目标的运动状态是科学的,且能够排除监控场景中噪声、背景等冗余信息对所要建立的运动模型带来的干扰。
基于混合高斯的背景建模算法是计算机视觉领域常用的一种运动前景区域提取方法。该算法具有检测效果佳、实时性较好等特点,至今仍然具有很高的实用价值。而针对混合高斯背景建模算法中构成每个像素的高斯数量需要人为确定的缺点,许多自适应混合高斯背景分割算法被提出来,可以自适应地确定混合高斯模型中的高斯数量,能够减少场景中光照变化、噪声等带来的干扰,同时减少计算量。本文主要采用Zivkovic改进的自适应混合高斯背景分割算法提取视频帧序列的运动前景[10]。并使用该文献中的参数设置。
图1为采用自适应混合高斯背景建模算法对视频帧图像进行的运动前景提取,从所得的前景图像可看出,即使图片分辨率低,运动目标表观模糊,算法的前景区域分割效果也很好。

图1 自适应混合高斯背景建模算法提取运动前景
Fig.1 Adaptive GMM model to extract moving foregrounds
3 运动前景效应图特征提取
异常行为检测阶段准确性的提高要求行人或其他物体运动的特征描述更加具有区分性。为克服直接使用如灰度梯度、光流直方图、动态纹理等低级视觉特征描述所造成的噪声高、区分度低的问题[4- 6],本文结合了行人实际运动模型,深入分析表现异常行为的行人或物体对周围环境所造成效应的不同,给出表示运动前景对周围环境造成效应的特征计算方法,将人群运动效应作为运动模型的高级特征描述,提出了一种基于运动前景效应图的特征描述。
图2 运动前景效应图特征提取框图
Fig.2 Motion effect map of moving foregrounds extraction
图2给出了本文的运动前景效应图特征的提取框图,算法首先由自适应混合高斯模型对视频帧序列做运动前景提取,并进行空间上分块得到运动前景块。然后根据视频帧的稠密光流获得运动前景块的运动矢量表示,最后计算所有运动前景块的效应获得效应图,并以连续多帧的空间子块作为空时块的形式提取空时块的效应图特征。
3.1 运动前景块提取
首先将自适应混合高斯模型提取的前景图在空间上分割成W×L个图像块,每个图像块尺度大小为N pixel×N pixel,由于重点在于分析运动行人或物体的各部分运动的效应,如人的手部挥动效应影响。故N的取定准则为:单个前景块可表示为运动前景目标的某一部分。其次,对图像块进行预处理,这是由于自适应混合高斯背景提取可能存在零星的前景点,这些前景点可能是噪声、背景细微变动或者是运动物体运动幅度较小造成的,无法明显地表示一个物体块的运动行为,特点是前景点在相应块内的数量占比小,其会对后续的效应图特征的计算产生干扰,故只有图像块内的前景点数量达到一定比例才能作为运动前景块。对分割出的每个图像分块做如下处理。
假设Bj(1≤J≤W×L)表示第j个图像分块,bj为其块内前景点数量,则只有满足公式(1)才能作为运动前景块保留,否则该分块作为噪声去除。
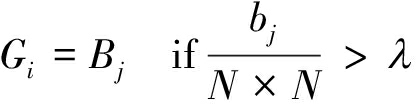
(1)
其中,Gi(1≤i≤S)表示图像块Bj在满足条件时可作为第i个运动前景块,λ为前景点比例阈值,取值可在0.1~0.4。
图3中左图为出现噪声点的前景图像,噪声干扰主要产生于图像的获取和传输过程,由于存在的噪声影响,造成某些背景像素点在时间序列中变化较大,短时间内形成了一个新的高斯分布,自适应混合高斯背景模型将其误判为前景点,因而前景图中存在孤立前景点。由于孤立点呈现数量少、随机分布的特点,图1中未出现噪声点,图3左图则表示了噪声点出现的情形。
图3中右图为使用公式(1)对前景图像作预处理效果图,通过预处理结果可以看出,将块内前景点占比小的图像块作为背景去除可以有效地去除零星的前景点,使所提取的运动前景块可以更有效地表示真实的运动物体。

图3 前景图像预处理
Fig.3 Preprocessing of foreground image
3.2 运动前景块的运动表示
运动前景块可表示为运动目标如行人或小车等目标的一部分实体,通过对前景块内像素点的光流信息可描述前景块的运动状态。文中先通过文献[11]所提出的稠密光流算法计算原始图像序列中每一帧每一像素点的光流矢量。为不失一般性,假设{G1,G2,...,GS}为所提取的运动前景块,通过取块内所有像素点光流矢量的平均作为当前块的光流矢量。
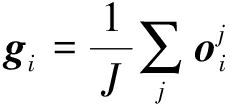
(2)
其中,gi表示第i个运动前景块的光流矢量,J为该前景块内所有像素点的数量,![]() 表示第i个运动前景块中第j个像素点的光流矢量。为了便于后续处理,假设‖gi‖和
表示第i个运动前景块中第j个像素点的光流矢量。为了便于后续处理,假设‖gi‖和![]() gi分别为第i个运动前景块光流的幅度和方向。
gi分别为第i个运动前景块光流的幅度和方向。
3.3 运动前景效应图特征计算
人群中单个行人运动方向容易受到很多影响因素的影响,例如道路上行驶的车辆、周围行人和其他障碍物。这些周围因素给行人带来的运动影响有效地被应用于人群运动模型建立[12-14]。文献[14]研究了物体块间相互影响的作用规律,但并没有考虑物体块对自身位置的影响。本文则从另一角度,将行人或其他运动目标给周围空间造成的影响称为运动效应,考虑周围空间分块受到运动前景块的效应主要取决于运动前景块的运动方向、运动速度和距离。
为了度量运动前景块Gi对周围空间块Bj是否产生影响效应,定义两个指标变量![]() 和
和![]()
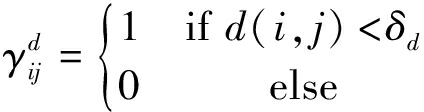
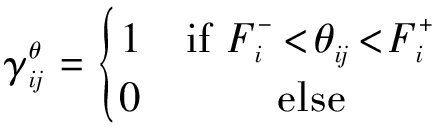
(3)
其中,d(i, j)表示运动前景块Gi和空间块Bj的欧式距离,δd为距离阈值,θij为从前景块Gi至空间块Bj的向量与Gi的光流之间的夹角,![]() 表示运动前景块运动时的视野范围,运动模型如图4所示。
表示运动前景块运动时的视野范围,运动模型如图4所示。
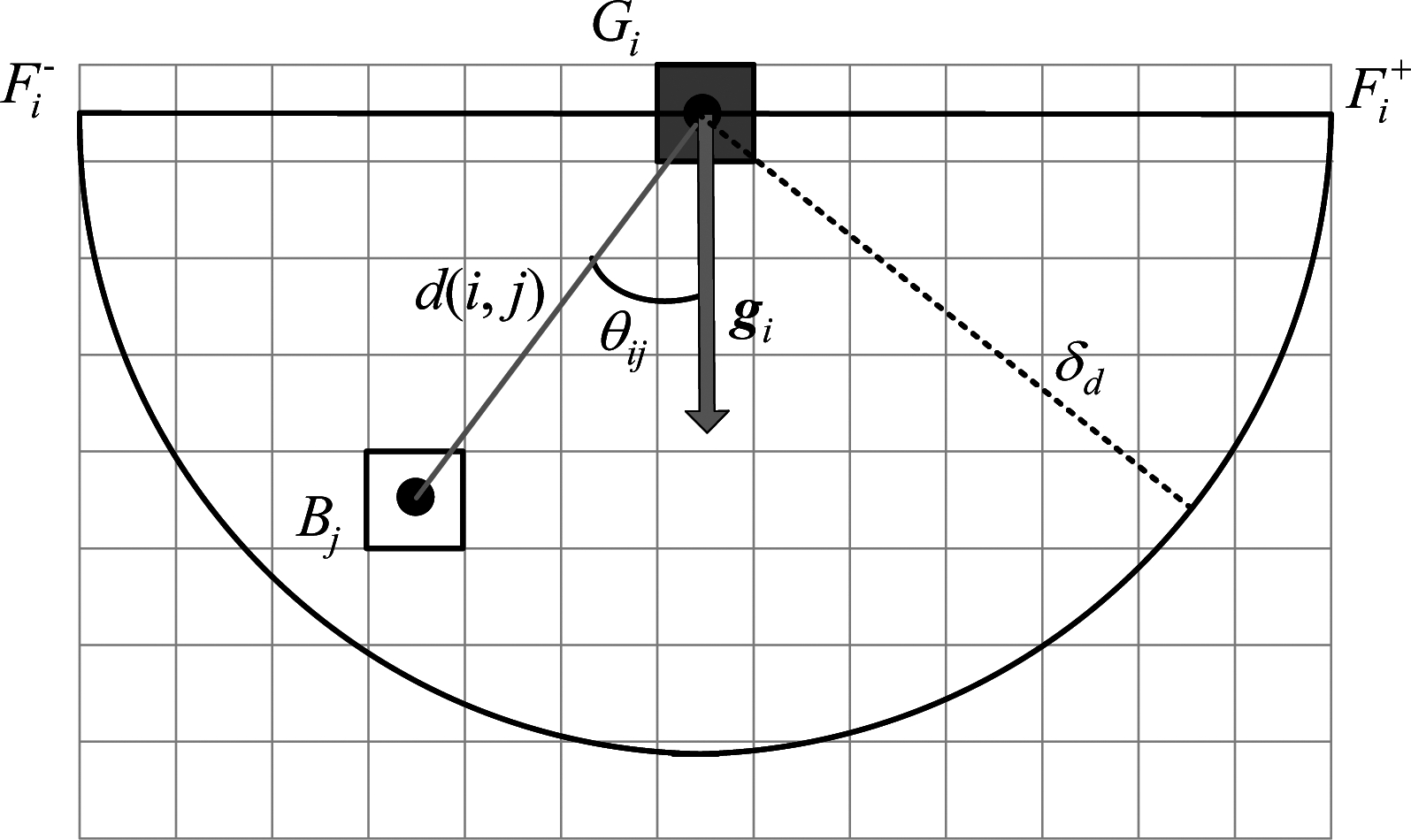
图4 前景块的运动模型图
Fig.4 Motion model of foreground block
故可定义运动前景块Gi对空间块Bj的效应权值为:
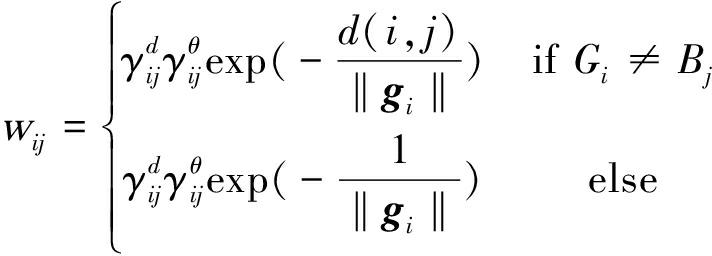
(4)
空间块Bj受到多个运动方向各不同的前景块带来的影响效应,需依据不同的运动方向对前景块的效应做统计,可以使提取的特征具有更高的区分度,为了计算效率,对运动前景块的运动方向作如下量化处理。
q(![]()
![]()
![]()
![]()
(5)
其中,k∈{1,2,3,...,p}, p为量化方向区间总数。
按照运动前景块光流的量化方向对前景块给空间块Bj产生的效应作统计如下。
hj(ki)=∑wij if q(![]() gi)=ki
gi)=ki
(6)
其中,ki表示第i个运动前景块光流的量化方向索引值。
在计算出所有空间块Bi的运动前景效应权值后,可构建视频序列中一帧图像的运动前景效应图,运动前景效应图的每一空间块均可由p维向量表示。为了在更长时间统计运动前景效应,使所提取特征具有更高区分性,取连续t帧的空间块作为一个空时分块,叠加t帧空间块的特征向量作为空时块的特征描述。
图5表示运动前景效应图特征的提取过程,相较于直接利用光流、表观等低级特征描述,表征运动目标空间上和时间上的运动效应的特征描述具有更高级的视觉特性。
4 改进的优化初始聚类中心K均值聚类算法
K均值聚类算法是一种可以将大量数据划分类别的简单有效算法,应用较为广泛。这种聚类算法存在着聚类中心数量需人为确定、不同的初始质心可导致不同聚类结果等缺点,其中,初始质心的选择很大程度上影响算法的聚类性能,目前仍未有既保证全局最优又聚类结果最好的解决方法[15]。
针对初始聚类中心优化问题,研究人员提出了很多改进方法。K-means++为戴维亚瑟等人于2007年提出的优化初始聚类中心的K均值聚类算法[16],其主要改进思想为:初始选定的聚类中心之间的距离应该保持尽可能远的距离,即选定本质上类别差异性大的初始聚类中心点。同样依据该思想的改进算法有最近邻选择法[17]、依据样本密集性选择法[18]。
为了获得固定的初始聚类中心,且算法具有较好的聚类效果,对文献[19]的最大距离初始化方法作出改进。首先计算样本集中所有样本点相互之间的距离,从中选取距离最大的两个样本点作为聚类中心集合,取离集合最远的点加入集合作为集合的更新,并以此类推,直至集合中聚类中心数量达到k个。
4.1 算法步骤
改进的最大距离初始化聚类中心算法的执行流程如下所示:
输入:数据集X={x1,x2,...,xn},xi∈Rd,聚类中心数k。
输出:k个初始聚类中心。
1)初始化聚类中心集合C=∅;
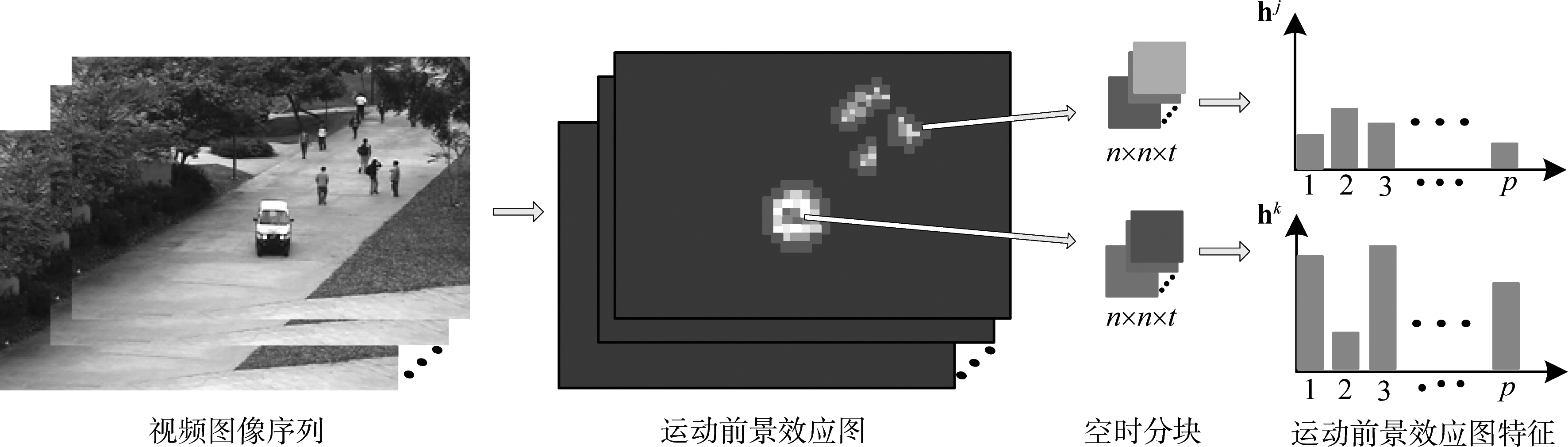
图5 运动前景效应图特征提取过程
Fig.5 Extracting motion effect map features of moving foregrounds
2)计算数据集中任意两个样本点之间的欧式距离,记xi,xj为距离最大的两个样本点,更新C={xi,xj};
3)记集合U=X-C,计算集合U中所有样本点与集合C的距离,距离公式为D(xp,C)=min D(xp,xl), xp∈U,xl∈C;
4)取![]() 将x*加入集合C;
将x*加入集合C;
5)重复步骤3)、4),直至集合C元素数量达到k个。
获得初始化的聚类中心后,使用经典K均值算法确定各类簇的聚类中心,目标函数为![]() 为聚类中心cj的样本集合。
为聚类中心cj的样本集合。
4.2 聚类结果评估
为验证改进的优化初始聚类中心K均值聚类算法的有效性,将算法与经典K均值算法、K-means++算法做比较。实验平台为MATLAB2013。使用UCI上常用的Iris、Wine、Seeds、User knowledge model (UKM)共4组数据集作为实验数据集,表1为数据集的属性。
表1 测试数据集属性
Tab.1 The properties of test datasets
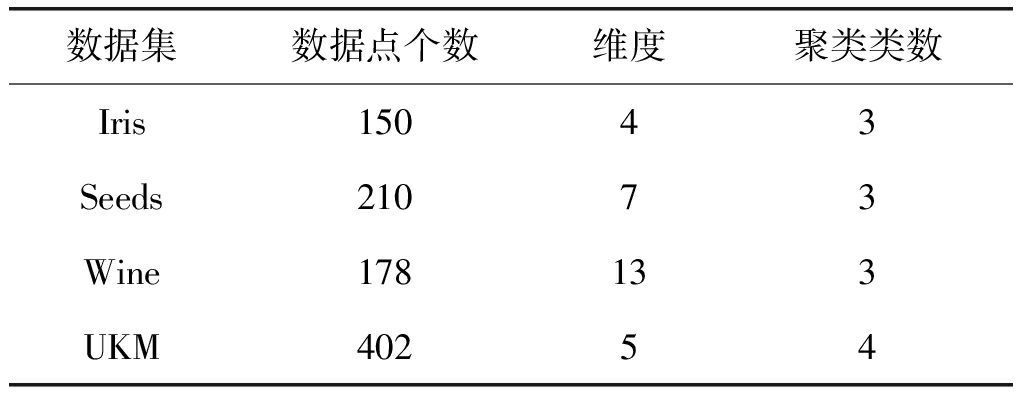
数据集数据点个数维度聚类类数Iris15043Seeds21073Wine178133UKM40254
由于K-means算法、K-means++算法所选取的初始聚类中心不是固定的,故对其取20次运行结果作为聚类效果衡量,使用误差平方和、聚类准确率作为聚类结果评估。
表2 聚类准确率结果
Tab.2 The accuracy result
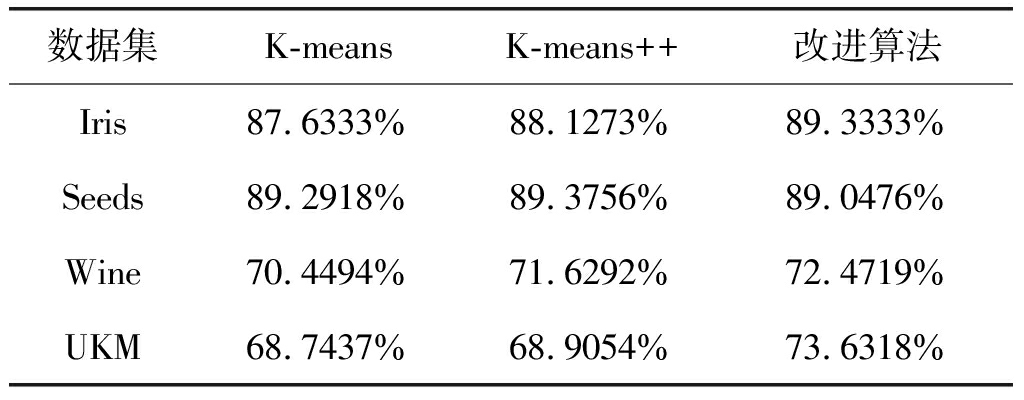
数据集K-meansK-means++改进算法Iris87.6333%88.1273%89.3333%Seeds89.2918%89.3756%89.0476%Wine70.4494%71.6292%72.4719%UKM68.7437%68.9054%73.6318%
表3 误差平方和结果
Tab.3 The sums of squared error result
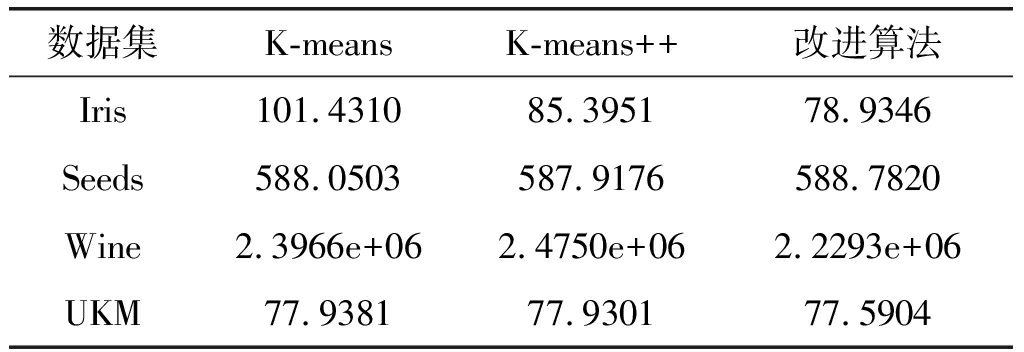
数据集K-meansK-means++改进算法Iris101.431085.395178.9346Seeds588.0503587.9176588.7820Wine2.3966e+062.4750e+062.2293e+06UKM77.938177.930177.5904
表2及表3为实验结果,与前两种算法比较,文中改进的算法在准确率和误差平方上有一定的改善,且能够获得固定的初始聚类中心,在应用于异常行为建模时避免了因为初始聚类中心不固定对聚类效果的干扰。
5 异常行为检测的算法框架
本文提出了一种基于运动前景效应图的统计特征,以一种改进的优化初始聚类中心K-means聚类方法对视频图像序列中运动前景的运动效应作训练分类,如算法整体框如图6所示。算法流程主要分为3个部分:运动前景分割;运动前景效应图特征提取;使用改进的优化初始聚类中心的K-means算法训练及分类。

图6 算法整体框架
Fig.6 The whole algorithm
5.1 运动前景效应图特征提取
首先使用文献[10]提取视频序列图像的运动前景区域,将图像切分为W×L个空间块,结合预处理的前景图像可提取运动前景块,运动前景块被用于计算每个空间块的运动效应权值特征向量,将时间上连续多帧的空间块特征累加形成运动前景效应图特征。
5.2 针对改进的K-means训练及分类
K均值聚类算法为常用的数据挖掘算法,可对大量数据进行聚类,文中针对其随机性初始化聚类中心的缺点作出改进,由于图像尺度在视频帧中不同位置时表现不一致,故对于不同位置的空时块均采用一个K-means模型做聚类训练,共有W×L个K-means聚类模型。
假设视频帧位置(i, j)处的一个已经过聚类训练的K-means模型的聚类中心集合为![]() 聚类中心建立了行人或物体正常运动的行为模式,则对于待检测视频帧同一位置处的空时块所提取的特征e(i, j),由公式(7)计算其与聚类中心集合的距离:
聚类中心建立了行人或物体正常运动的行为模式,则对于待检测视频帧同一位置处的空时块所提取的特征e(i, j),由公式(7)计算其与聚类中心集合的距离:
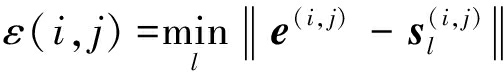
(7)
通过设定阈值Tε判断ε(i, j)是否为离群点,如果ε(i, j)>Tε,则可将该空时块标记为异常,可实现对视频中异常行为的检测和定位。
6 实验与分析
实验使用Intel(R) Core(TM) i7处理器、8.00 GB内存台式电脑,使用C++、Matlab编程实现。实验采用由文献[20]于2010年提出的UCSD异常检测视频数据集,为现阶段认可度较高的公开数据集。
6.1 实验参数设定
UCSD视频数据集包含2个不同自然场景的视频集,分别为Ped1和Ped2,其中定义了许多异常行为对象,如:滑轮者、货车、坐轮椅者、巡逻车、骑自行车者。Ped1的图像分辨率为238 pixel×158 pixel,包含34段训练样本和36段测试样本;Ped2的图像分辨率为360 pixel×240 pixel,包含16段训练样本和12段测试样本。所有测试样本均给出标出异常行为对象的基准帧。
文中运动前景块的大小表示的是运动行人或物体的一部分,故空间分块需结合图像中行人表观分辨率而定,将Ped1空间分块大小设为8 pixel×8 pixel,Ped2空间分块大小设为12 pixel×12 pixel,由于时间分块目的在于获取短时内的运动行为表示,则可设定t=4。前景点比例阈值根据实际情况可设定λ=0.1。运动前景块影响视野范围设为[-π,π],距离范围随着运动幅值而变化,故设定δd=‖gi‖×n×n,光流量化方向p依据实验效果设定为8,改进的K均值聚类类数设为5,足够表征人群的正常行为。
6.2 异常行为检测算法准确率评估
提取运动前景图的视频理论上更有利于异常行为的检测,故为了验证所提出算法利用前景图的有效性与整体检测方案的准确性。从两方面进行实验比较,一为与基于前景信息的方法之间的实验比较,另一方面为与现有其他检测方法之间的实验比较。
6.2.1 基于前景信息的检测算法实验比较
将所提出算法(简称为Ours)与其他两种基于前景信息的异常行为检测算法做比较,分别为基于区域的轨迹分析与路径预测[21] (简称为Region-Based)、空时卷积神经网络[22] (简称为ST-CNN)。前者重点分析前景存在的区域,而后者间接利用运动前景信息,提取运动信息显著的空时块作为重点分析对象。此外,为分析改进的K均值聚类在所提出算法中的作用,将所提出的运动前景效应图特征和经典K均值聚类结合的算法(简称为MEM-kmeans)进行比较。
图7为Ours算法与其他几种基于前景的检测算法之间的ROC曲线比较,在数据集Ped1上,Region-Based具有最好的ROC曲线,其他三种算法基本较为接近;在数据集Ped2上,Ours算法与MEM-Kmeans表现相当,并比其他两种方法好。
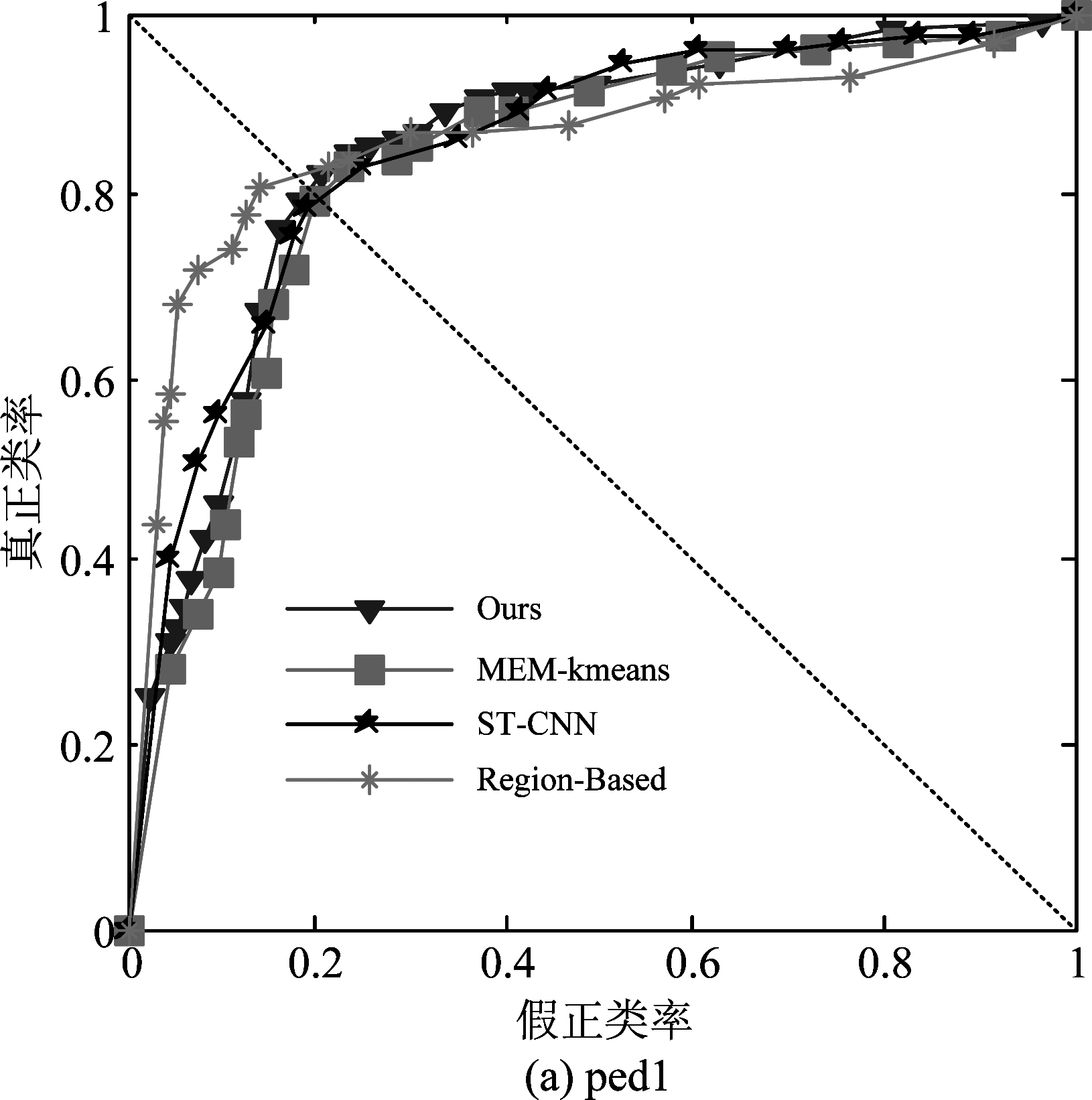
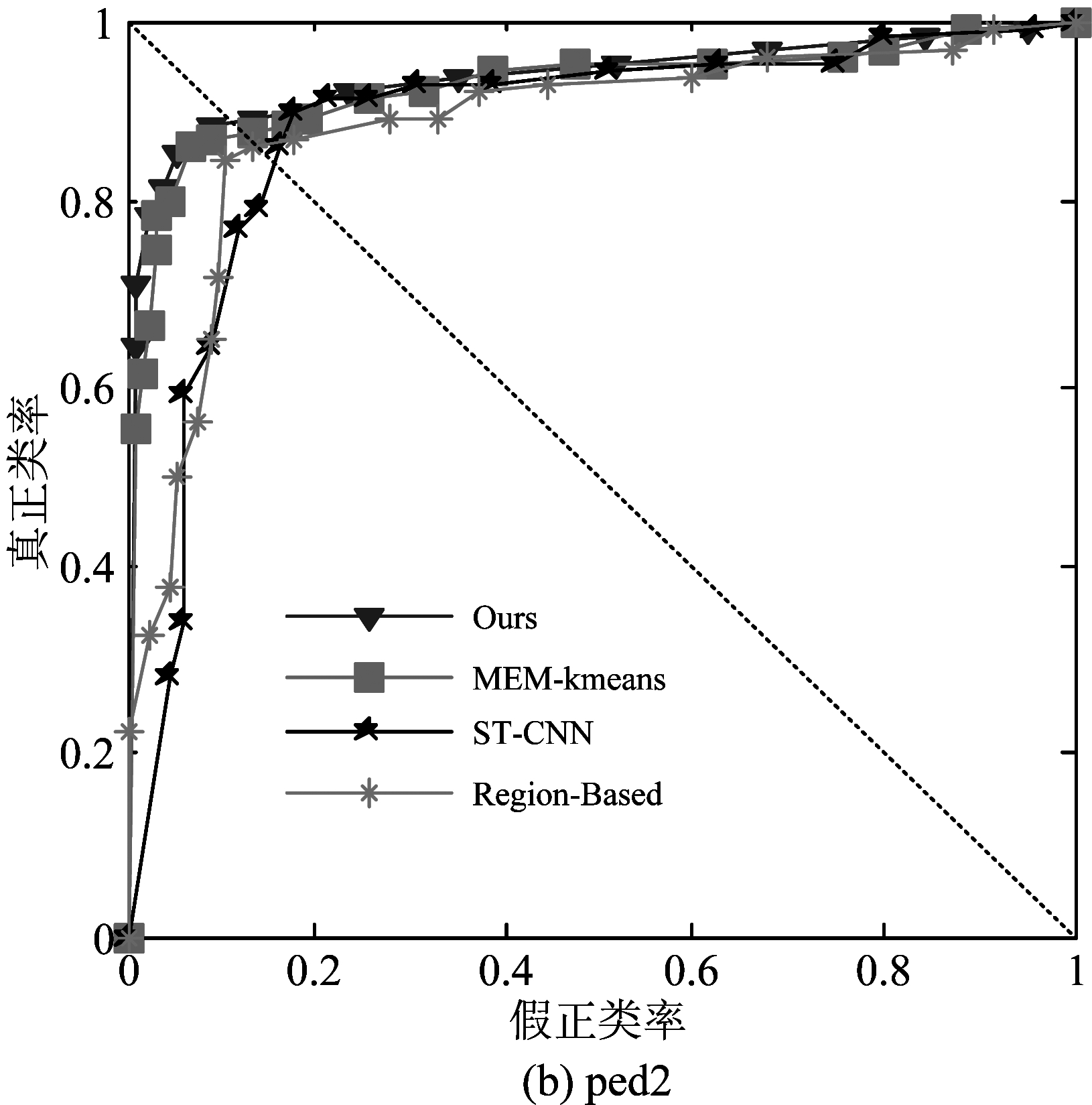
图7 UCSD数据集上基于前景的检测算法的ROC曲线比较
Fig.7 ROC curve for different foreground-based algorithms on UCSD dataset
表4和表5分别为通过AUC(Area Under Curve)、EER(Equal Error Rate) 这2个重要的量化评估指标的评估结果。评估实验为帧级(flame-level)的检测评估。
表4 UCSD数据集上基于前景的检测算法的AUC指标对比
Tab.4 The AUC for different foreground-based algorithms on UCSD dataset
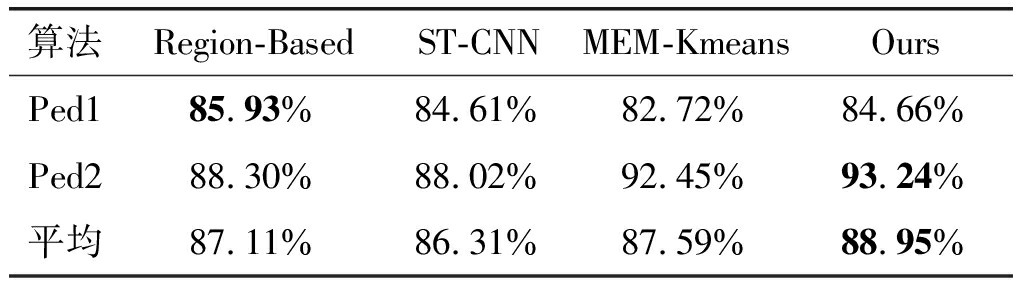
算法Region-BasedST-CNNMEM-KmeansOursPed185.93%84.61%82.72%84.66%Ped288.30%88.02%92.45%93.24%平均87.11%86.31%87.59%88.95%
由表4可得在场景Ped1下,Region-Based的AUC指标值比Ours算法高出1.27个百分点,Ours算法与ST-CNN的AUC指标值则基本相等;在场景Ped2下,Ours的AUC最佳。而无论Ped1还是Ped2,Ours的AUC指标值与MEM-Kmeans方法的AUC值最为接近。
表5 UCSD数据集上基于前景的检测算法的EER指标对比
Tab.5 The EER for different foreground-based algorithms on UCSD dataset
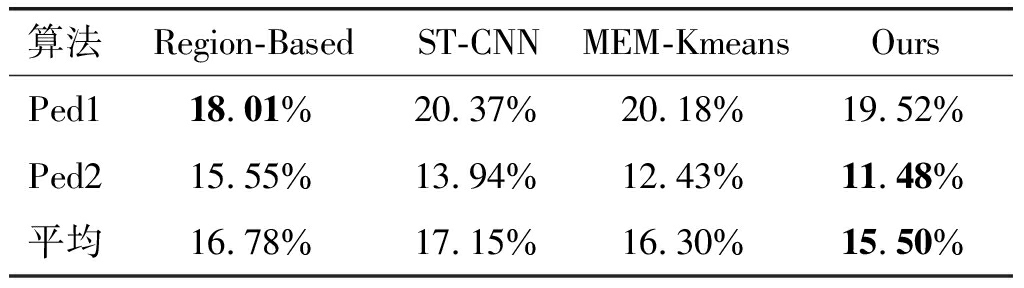
算法Region-BasedST-CNNMEM-KmeansOursPed118.01%20.37%20.18%19.52%Ped215.55%13.94%12.43%11.48%平均16.78%17.15%16.30%15.50%
表5中在场景Ped1下,Ours算法低于Region-Based方法1.51个百分点,为19.52%,但要优于ST-CNN的20.37%;在场景Ped2下,Ours算法比Region-Based提高了4.07%。此外,总体上,Ours算法只比MEM-Kmeans提高了0.8%的指标值。
故整体上看,Ours算法取得最佳的准确率。Region-Based在Ped1具有最佳的表现,其对帧间前景信息进行了较为深入的轨迹分析。Ped2视频集具有更高的分辨率,Ours算法则可对运动前景块建立更为有效的运动模型。无论Ped1数据集还是Ped2数据集,MEM-Kmeans与整体Ours算法表现均十分接近,表明了异常行为检测有效性的提高更多的是特征提取的改进,而改进的K均值聚类则是为了避免K均值聚类中心不固定导致聚类模型不稳定的缺点。
6.2.2 其他检测算法实验比较
为验证所提出算法(简称为Ours) 的准确性,将Ours算法与现有的其他几种算法作比较,这些检测方案并无利用前景信息,分别为:社会力模型[12](简称SF)、运动影响图[14](简称Dong-Gyu)、局部光流直方图[23](简称SL-HOF)。其中局部光流直方图为Siqi Wang 于2016年提出的算法。
图8为所提出算法和其他3种对比算法在Ped1和Ped2上的ROC曲线对比。Ours算法具有最佳的ROC曲线。
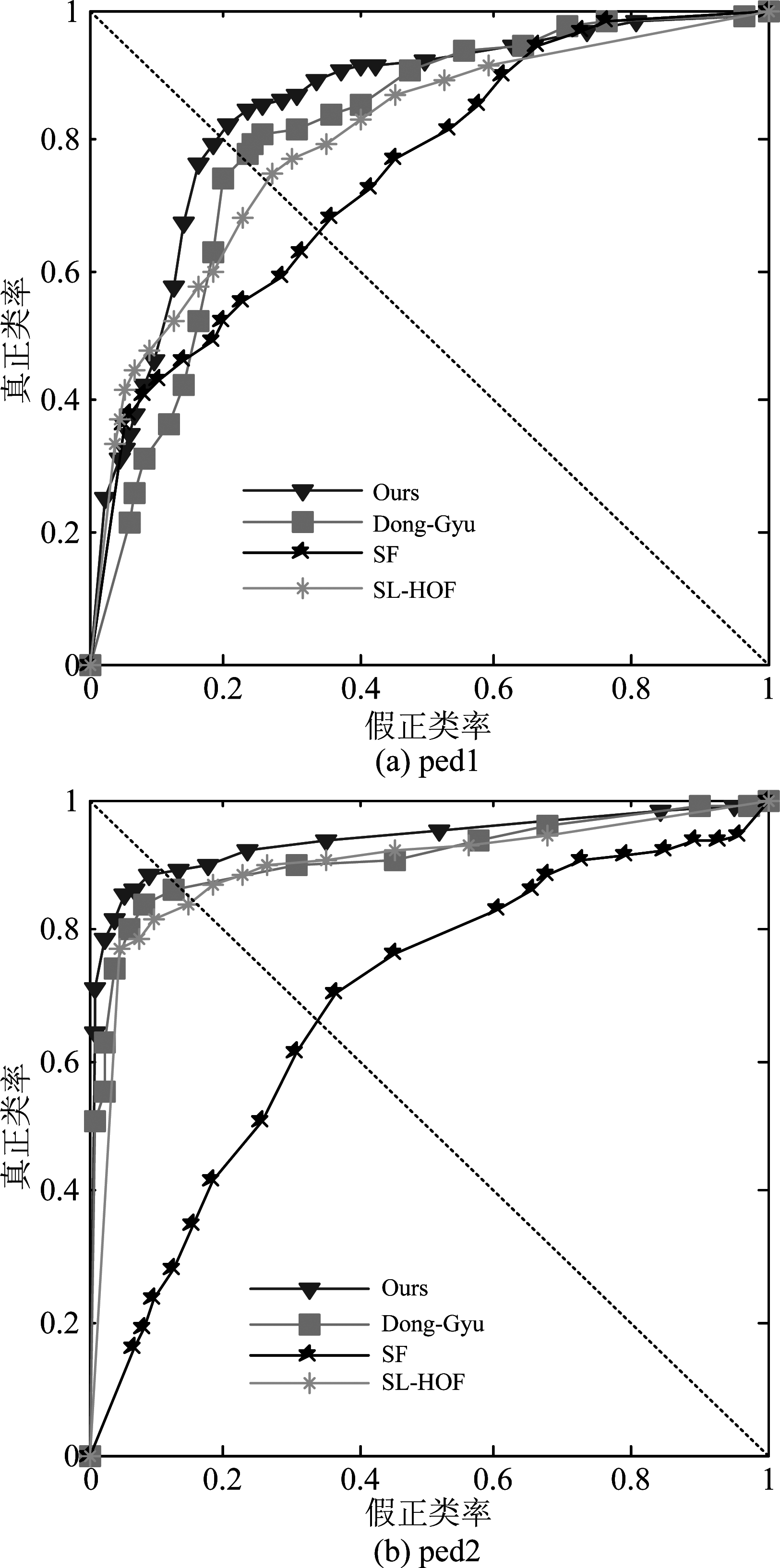
图8 UCSD数据集不同算法的ROC曲线比较
Fig.8 ROC curve for different algorithms on UCSD dataset
表6 UCSD数据集上不同算法的AUC指标对比
Tab.6 The AUC for different algorithms on UCSD dataset
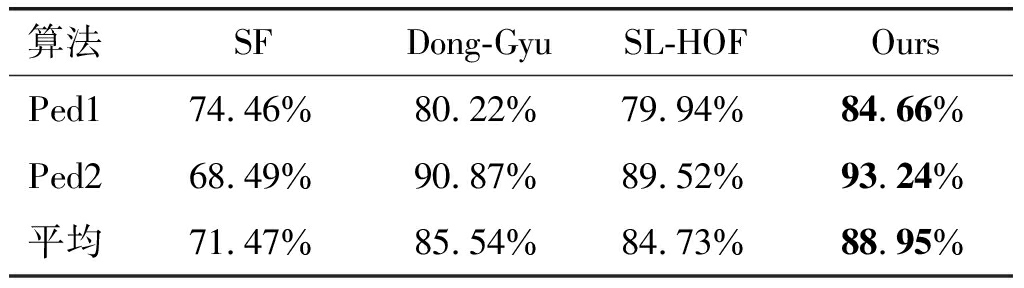
算法SFDong-GyuSL-HOFOursPed174.46%80.22%79.94%84.66%Ped268.49%90.87%89.52%93.24%平均71.47%85.54%84.73%88.95%
表6为本文算法及其他对比算法在UCSD数据集上的AUC指标值对比。在数据集Ped1上,本文的AUC为84.66%,比Dong-Gyu提高了4.44%,与SL-HOF相比,则提升了4.72%;在数据集Ped2上,Ours比Dong-Gyu高了2.37%,与SL-HOF相比,也有较高的提升。这得益于重点分析前景目标的运动模式,而滤除背景冗余信息的影响。
表7 UCSD数据集上不同算法的EER指标对比
Tab.7 The EER for different algorithms on UCSD dataset
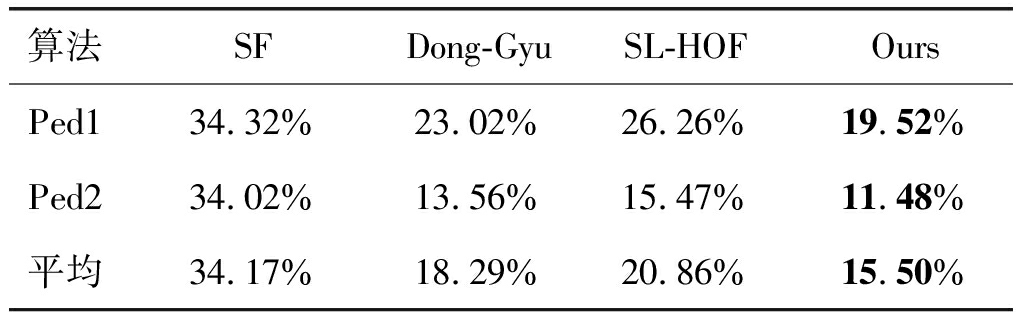
算法SFDong-GyuSL-HOFOursPed134.32%23.02%26.26%19.52%Ped234.02%13.56%15.47%11.48%平均34.17%18.29%20.86%15.50%
表7为本文算法与其他现有几种算法在数据集UCSD上的EER指标值对比。对于各种算法在Ped1上的EER指标值,相较于Dong-Gyu和SL-HOF,Ours分别提升了3.5%和6.74%;而在Ped2上,Ours为11.48%,比Dong-Gyu提升了2.08%,与SL-HOF相比,也有3.99%的提升。
图9为文中算法对测试视频序列中异常行为对象的定位效果图,由于重点针对稀密不同的人群正常运动视频序列做特征提取及聚类训练,图(e)与(f)表明人数稀疏、密集出现的异常行为对象均可进行有效地检测。

图9 测试序列图像出现的异常行为对象的定位
Fig.9 Location of abnormal objects in abnormal frame
7 结论
本文提出了一种基于运动前景效应图特征的人群异常行为检测算法,通过自适应混合高斯背景建模方法得到视频序列的前景图像,并通过块内前景点筛选的预处理方法分割得前景图像块,计算运动前景的效应图,并以空时块为单位提取运动前景效应图特征,以一种改进的优化初始聚类中心的K均值聚类算法判定待检测空时块的特征表示是否为离群点。
通过与其他算法在公认UCSD数据集上的实验比对,本文算法在AUC和EER指标上有一定的提高,并且可以定位异常行为的位置。
参考文献
[1] 吴新宇, 郭会文, 李楠楠,等.基于视频的人群异常事件检测综述[J]. 电子测量与仪器学报, 2014, 28(6):575-584.
Wu Xinyu, Guo Huiwen, Li Nannan, et al. Survey on the video-based abnormal event detection in crowd scenes[J]. Journal of Electronic Measurement and Instrumentation,2014,28(6):575-584.(in Chinese)
[2] Rabiee H, Haddadnia J, Mousavi H.Crowd behavior representation: an attribute-based approach[J].SpringerPlus,2016,5(1):1179-1195.
[3] Popoola O P, Wang K. Video-Based Abnormal Human Behavior Recognition—A Review[J]. IEEE Transactions on Systems Man & Cybernetics Part C, 2012, 42(6):865- 878.
[4] Mohammadi S, Kiani H, Perina A, et al. Violence detection in crowded scenes using substantial derivative[C]∥IEEE International Conference on Advanced Video and Signal Based Surveillance, 2015:1- 6.
[5] Li A, Miao Z, Cen Y, et al. Abnormal event detection based on sparse reconstruction in crowded scenes[C]∥IEEE International Conference on Acoustics, Speech and Signal Processing, 2016:1786-1790.
[6] Duan S, Wang X, Yu X. Crowded abnormal detection based on mixture of kernel dynamic texture[C]∥International Conference on Audio, Language and Image Processing,2015:931-936.
[7] Mousavi H, Mohammadi S, Perina A, et al. Analyzing Tracklets for the Detection of Abnormal Crowd Behavior[C]∥IEEE Winter Conference on Applications of Computer Vision,2015:148-155.
[8] Li Z, Chen L, Ren Z, et al. A pattern recognition for group abnormal behaviors based on Markov Random Fields energy[C]∥IEEE International Conference on Cognitive Informatics & Cognitive Computing, 2014:526-528.
[9] 柳晶晶, 陶华伟, 罗琳,等.梯度直方图和光流特征融合的视频图像异常行为检测算法[J].信号处理, 2016, 32(1):1-7.
Liu Jingjing, Tao Huawei, Luo lin, et al. Video Anomaly Detection Algorithm Combined with Histogram of Oriented Gradients and Optical Flow[J]. Journal of Signal Processing, 2016, 32(1):1-7. (in Chinese)
[10] Zivkovic Z. Improved Adaptive Gaussian Mixture Model for Background Subtraction[C]∥International Conference on Pattern Recognition, 2004:28-31.
[11] Farnebäck G. Two-Frame Motion Estimation Based on Polynomial Expansion[M]. Image Analysis. Springer Berlin Heidelberg, 2003:363-370.
[12] Mehran R, Oyama A, Shah M. Abnormal crowd behavior detection using social force model[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2009:935-942.
[13] Chaker R, Junejo I N, Aghbari Z A. Crowd modeling using social networks[C]∥IEEE International Conference on Image Processing, 2015:1280-1284.
[14] Lee D G, Suk H I, Park S K, et al. Motion Influence Map for Unusual Human Activity Detection and Localization in Crowded Scenes[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2015, 25(10):1612-1623.
[15] Choudhary A, Sharma P, Singh M. Improving K-means through better initialization and normalization[C]∥2016 International Conference on Advances in Computing,Communications and Informatics (ICACCI), Jaipur, 2016: 2415-2419.
[16] Arthur D, Vassilvitskii S. k-means++: the advantages of careful seeding[C]∥Eighteenth Acm-Siam Symposium on Discrete Algorithms Society for Industrial and Applied Mathematics, 2007:1027-1035.
[17] Kettani O, Tadili B, Ramdani F. A Deterministic K-means Algorithm based on Nearest Neighbor Search[J]. International Journal of Computer Applications, 2013, 63(15):33-37.
[18] Xiong C, Hua Z, Lv K, et al. An Improved K-means Text Clustering Algorithm by Optimizing Initial Cluster Centers[C]∥2016 7th International Conference on Cloud Computing and BigData (CCBD), Macau, China, 2016:265-268.
[19] Rajaraman A, Ullman J D. Mining of massive Datasets[M]. 2nd ed. Cambridge University Press, 2014:252-254.
[20] Mahadevan V, Li W, Bhalodia V, et al. Anomaly detection in crowded scenes[C]∥Computer Vision and Pattern Recognition, 2010:1975-1981.
[21] Zhang T, Wiliem A, Lovell B C. Region-Based Anomaly Localisation in Crowded Scenes via Trajectory Analysis and Path Prediction[C]∥International Conference on Digital Image Computing: Techniques and Applications. IEEE, 2013:1-7.
[22] Zhou S, Shen W, Zeng D, et al.Spatial-temporal Convolutional Neural Networks for Anomaly Detection and Localization in Crowded Scenes[J]. Signal Processing Image Communication, 2016, 47:358-368.
[23] Wang S, Zhu E, Yin J, et al. Anomaly detection in crowed scenes by SL-HOF descriptor and foreground classification[C]∥ 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, 2016:3398-3403.


