1 引言
表情是反应人们精神和情感的面部运动,人们在交流时约55%的信息通过表情传递,因此它在社会交际中扮演重要角色,表情识别相关研究也成为热点。然而,对表情的研究大多集中在传统表情,即宏观表情或全表情,而对微表情的研究相对较少。直到最近,越来越多的学者才开始关注微表情的研究。
微表情难以被察觉,其持续时间仅为1/ 25 s至1/5 s;微表情既可能含普通表情的全部肌肉动作,也可能只包含一部分;它表达了人类试图隐藏的真实情感,是自发性表情。微表情的上述性质,使它成为了解人类真实情感的窗口。因此,微表情有非常多的潜在应用,如刑侦破案、国防安全、临床诊断、人机交互等。但微表情持续时间短、发生强度低和通常只涉及局部运动的特点,对微表情的识别带来了极大挑战。Ekman和Friesen在进行测谎研究时第一次提出了微表情的概念,之后Ekman在研究中发现,只有不到1%的人可以在没经过特殊训练的情况下检测微表情,因此Ekman等开发了一套微表情训练工具(Micro-Expression Training Tool, METT)来提升人们对微表情的感知能力。随着计算机视觉的发展,一些研究者开始尝试提取各种特征用于微表情识别。Zhao等[1]提出了一种基于三个正交平面的动态LBP特征(Local binary pattern from three orthogonal planes, LBP-TOP)进行微表情识别, Pfister等[2]设计了一个双阶段系统第一次实现了自发微表情识别,在第一阶段,系统采用了时域差值模型(Temporal Interpolation Model, TIM)对微表情序列的总帧数进行归一化,以此来解决短时视频的问题;在第二阶段,系统通过LBP-TOP提取时空局部纹理描述子(Spatiotemporal Local texture descriptor, SLTD)实现微表情的识别。Huang等[3]在STLBP-IP[4]的基础上,采用RPCA[5]法提取微表情的细微运动来替换差分图像,并结合一种基于拉普拉斯的特征选择方法来增强类与类之间的区分性,提出了一种基于改进积分投影技术的差分时空LBP(DiSTLBP-RIP)特征,并在微表情识别方面取得了较好效果。除了基于LBP的特征之外,Polikovsky等[6]提出了一种3D梯度描述子(3D-gradient descriptor)并结合K均值(K-means)算法来识别微表情发生的三个阶段和情感类别。此外,随着光流在行为检测[7]和行为识别[8]等方面的广泛应用,Li等[9]提出了一种基于深度学习的HOOF特征用于微表情检测,Liu等[10]提出了一种MDMO(Main Directional Mean Optical-flow)特征来实现微表情识别并取得了较好效果。另一方面,随着深度学习在动作识别[11]、人脸认证[12]、表情识别[13]等方面的成功应用,Patel等[14]将深度学习应用于微表情识别,但由于深度学习依赖大规模数据集,其所提深度特征的识别率未超过传统特征的识别率。
本文提出了一种新的基于平均光流方向直方图(Mean Histogram of Oriented Optical Flow, MHOOF)的微表情识别算法。为了提取更加准确有效的特征,所提算法首先提取稠密人脸关键点并根据面部运动单元对人脸区域进行ROI划分,然后提取选定ROI内相邻两帧之间的HOOF(Histogram of Oriented Optical Flow, HOOF)特征实现对峰值帧的检测。本文进行峰值帧检测的原因有两点:一是从起始至峰值这一段序列中,MHOOF特征可以更好地描述微表情的状态,二是更短的图片序列可以减少头部姿态带来的影响。在特征提取和识别阶段,所提算法提取从起始帧到峰值帧表情序列的MHOOF特征并利用SVM分类器实现微表情的识别。
本文的组织结构如下:第2节详细介绍了基于MHOOF特征的微表情识别算法,第3节是实验细节和实验结果,第4节是对MHOOF算法的总结。
2 基于MHOOF特征的微表情识别算法
基于MHOOF特征的微表情识别的整体结构如图1所示,由于微表情通常只涉及局部运动,所提算法通过划分特定的ROI来细化特征提取的范围同时排除无关区域的干扰,然后提取选定ROI内的HOOF特征检测微表情序列的峰值帧,最后提取从起始帧到峰值帧的图片序列的 MHOOF特征,利用SVM分类器实现微表情的识别。
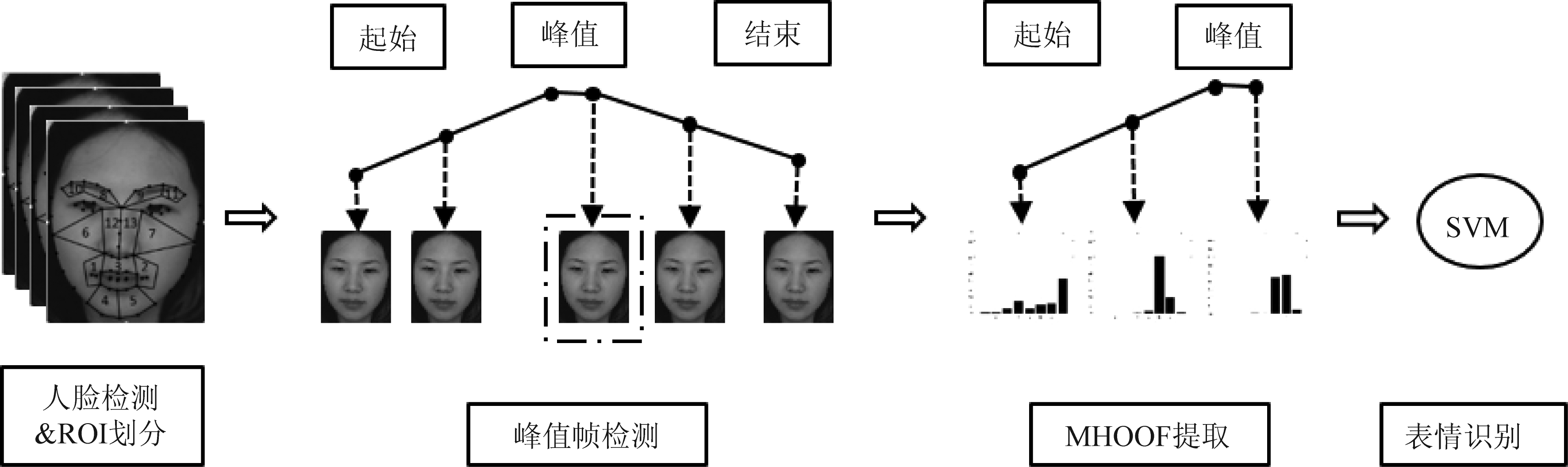
图1 基于MHOOF特征的微表情识别系统框图
Fig.1 Micro-expression recognition system framework based on MHOOF feature
2.1 人脸关键点检测和感兴趣区域划分
对于ROI划分,首先要精确地检测出稠密人脸关键点。本文采用Baltrušaitis等[15]提出的人脸行为分析工具OpenFace来提取人脸关键点。该工具在CLNF(Constrained Local Neural Model)[16]的基础上,首先采用dlib library提供的人脸检测器检测出人脸框,然后学习一个从人脸框到68个人脸关键点边界的简单线性映射来初始化CLNF模型,之后使用新提出的局部神经场(Local Neural Field, LNF)来计算更多可靠的映射关系图,并采用Non-Uniform Regularised Mean-Shift作为最优化方法,将每个区域的可靠性考虑在内从而使结果更加准确。此外OpenFace还对眼睛、嘴唇和眉毛分别训练关键点分布模型,并将这些关键点进行融合,该算法的检测效果优于之前的CLM[17]、DRMF[18]。68个人脸关键点的检测效果如图2所示。
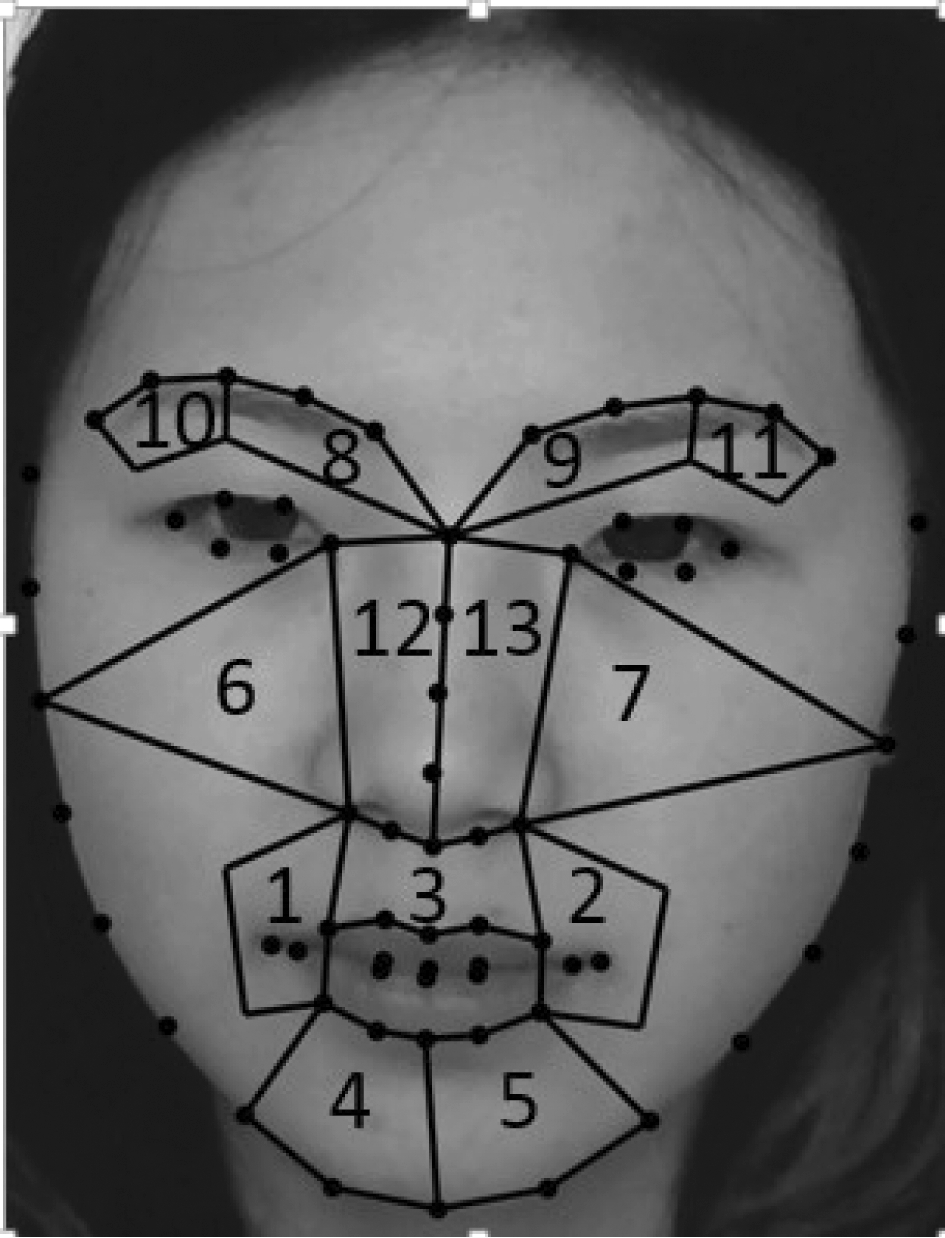
图2 68个人脸关键点的检测和13个ROIs的分布
Fig.2 The detected 68 facial landmarks and distribution of 13 ROIs
检测到稠密人脸关键点后,我们根据关键点的坐标和FACS将人脸区域划分成13个ROIs,如图2所示。FACS根据面部一块或多块肌肉的收缩或舒张状态定义动作单元(Action Unit, AU),通常一个AU对应面部的一个局部运动,因此AU经常被用于分析面部运动情况。本文划分的13个ROIs和对应的AUs如表 1所示。ROI的划分有多种策略,但总的原则是ROI的划分既不能太稀疏也不能太稠密,如果划分太稀疏,有可能漏掉有用信息,而如果划分太稠密,又可能引入冗余信息。根据Liong等[19]对面部区域出现频率的统计情况,眉毛和嘴巴是在微表情发生过程中出现频率最高的区域,因此我们对这些区域进行更细致地划分,而对脸颊和额头等区域则划分地比较稀疏。在之前的许多划分策略中,眼睛区域也经常作为一个重点对象,但眨眼动作在任何表情任何阶段都有可能发生,因此该区域可能会带来更多的误导信息,所以本文只对眉毛区域进行了划分。同时,根据面部区域运动的情况,本文选择和微表情发生最紧密相关的区域,尽量将ROI划分地稀疏,和Liu等[10]将人脸区域划分成36个ROI相比,本文的划分方法既排除了非重点区域的干扰,也降低了MHOOF特征的维数,如我们将光流方向划分成8个区间,则一帧中MHOOF特征的维数是1![]() 8=104维(本文只选用光流的方向参数)。
8=104维(本文只选用光流的方向参数)。
表1 13个ROIs和对应的AUs及面部运动情况
Tab.1 The 13 ROIs with corresponding AUs and facial movements
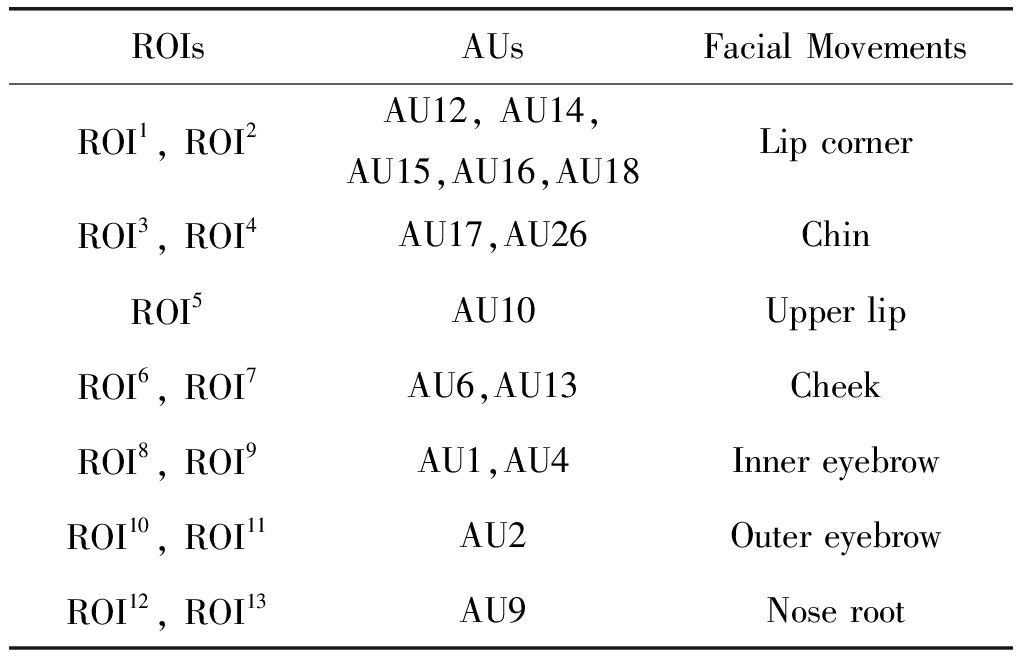
ROIsAUsFacial MovementsROI1, ROI2AU12, AU14,AU15,AU16,AU18Lip cornerROI3, ROI4AU17,AU26ChinROI5AU10Upper lipROI6, ROI7AU6,AU13CheekROI8, ROI9AU1,AU4Inner eyebrowROI10, ROI11AU2Outer eyebrowROI12, ROI13AU9Nose root
2.2 光流场
光流用来估计发生在时间t和t+Δt的两帧图片之间的相对运动,目前有两种光流计算技术:稠密光流和稀疏光流,但稠密光流的计算复杂度高于稀疏光流的,因此通常采用的是LK(Lucas-Kanade)光流算法[20],该算法基于以下三点假设:
(1)亮度恒定。即图片中像素点的亮度值在一个非常短的时间内不变。
(2)微小运动。即图片中像素块的运动尺度和帧与帧之间的时间变化相比是非常小的。
(3)空间一致性。即图片中邻域内的像素点有相同的运动。
假设在时间t和t+Δt时,一帧图片中一个像素点的亮度值分别是I(x,y,t)和I(x+Δx,y+Δy,t+Δt),基于第一条“亮度恒定”的假设,可以得到:
I(x,y,t)=I(x+Δx,y+Δy,t+Δt)
(1)
同时根据第二条“微小运动”的假设,对式(1)进行泰勒展开:
I(x+Δx,y+Δy,t+Δt)=I(x,y,t)+
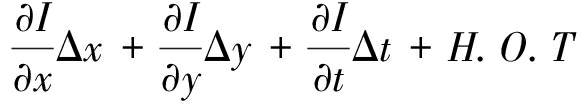
(2)
忽略2阶以上的高阶项并结合式(1)可得:
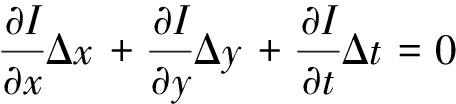
(3)
当Δt→0时有:
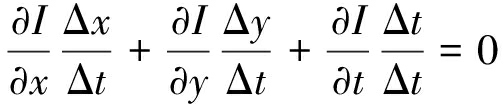
(4)
或:
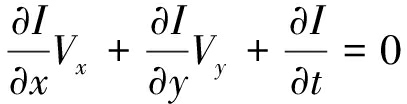
(5)
其中Vx,Vy分别是光流运动速度的x和y分量,用Ix,Iy和It来表示其导数形式,可得:
IxVx+IyVy=-It
(6)
由式(6)可知,对于一个像素点有两个未知参数,为了解决这个问题,LK光流算法还需依赖第三个假设即空间一致性。若在当前像素点周围选择一个![]() 5的窗口,则可得到如下25个等式:
5的窗口,则可得到如下25个等式:
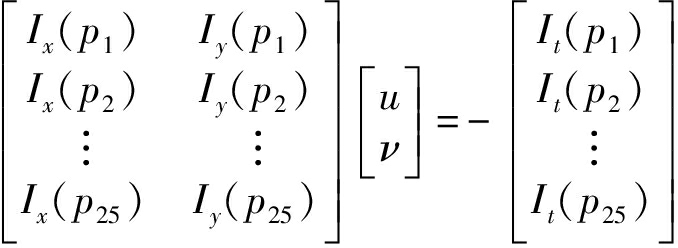
(7)
LK算法采用最小二乘估计方法通过使![]() 最小化来解决式(7)的过约束问题,其标准形式如下:
最小化来解决式(7)的过约束问题,其标准形式如下:
(ATA)d=ATb
(8)
将式(7)转换成如下形式:
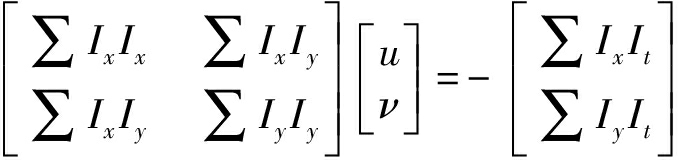
(9)
最后可得:
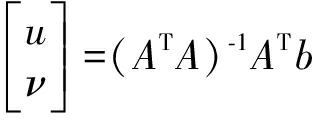
(10)
由于LK算法基于一个滑动的局部小窗口,因此不适用于那些较大的可能会移出窗口的运动,为了解决这个问题,Bouguet等[21]提出了一种金字塔LK光流算法(Pyramidal LK optical flow algorithm),该算法从图片金字塔的最高层开始计算出光流和仿射变换矩阵,然后将计算结果作为初始值传递给下一层图像,这一层的图像在初始值的基础上同样计算出光流和仿射变换矩阵,然后将结果传递给下一层,以此类推,直至最后一层即原始图像,其计算出的光流作为最后结果。
2.3 峰值检测
人脸对齐是人脸识别中常用的预处理方法,但是在人脸对齐后会引起面部一定程度的变形,这对强度非常低的微表情就会产生较大影响。另外考虑到微表情发生的时间非常短,帧与帧之间的变化程度很小,因此本文没有进行传统的人脸对齐,而是首先进行峰值帧检测。一个完整的微表情序列可以分为开始发生、正在发生和结束三个阶段,其中开始发生和正在发生阶段可以更好地反映微表情类别,如一个类别为高兴的微表情通常会伴随着嘴角上扬,而其回落阶段对于微表情的识别并没有太多有效信息,此外更短的微表情序列可以减少头部姿态变化引起的噪声,因此通过峰值检测就可以选取从起始帧到峰值帧的微表情序列。本文采用我们前期工作所提出的峰值检测算法[22],首先提取眉毛、嘴角和下巴周围5个区域内相邻两帧之间的光流场(如图4(b)所示),然后将光流方向划分成8个区间(如图3所示)。
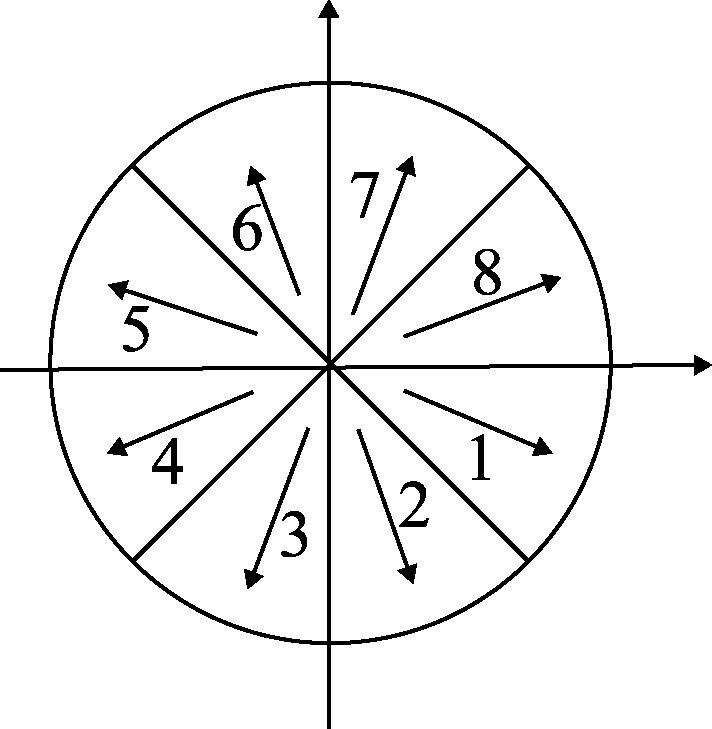
图3 8个光流方向区间的划分
Fig.3 The partition of 8 direction bins of optical flow
最后计算每个区域R内的HOOF特征(如图4(c)所示)并统计方向向下的像素点之和及方向向上的像素点之和,二者的差值δ如下所示:
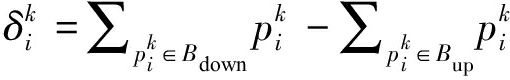
(11)
其中i=1,2,…,n是微表情序列的帧的索引,k=1,2,…,5是5个区域R的编号,![]() 是属于
是属于![]() 的像素点p,Bdown是方向向下即区间1、2、3、4的集合,Bup是方向向上即区间5、6、7、8的集合。δ正负值的改变表示运动方向的改变,因此峰值帧即为δ正负改变时的帧数。
的像素点p,Bdown是方向向下即区间1、2、3、4的集合,Bup是方向向上即区间5、6、7、8的集合。δ正负值的改变表示运动方向的改变,因此峰值帧即为δ正负改变时的帧数。

图4 类别为“高兴”的微表情序列的光流变化。由于篇幅限制,在(a)和(b)中我们只选取了第2、5、9、10、17、22总共6帧,其中第2、5、9帧属于“开始发生”阶段,第10帧属于“正在发生”阶段,第17、22帧属于“结束”阶段。我们以ROI1(右嘴角)为例,展示了微表情在各个阶段中光流方向的变化
Fig.4 The optical flow of a micro-expression sequence labeled “happiness”. For the limited space, we only select six frames in (a) and (b): 2nd, 5th, 9th, 10th, 17th, and 22nd, where the 2nd, 5th, 9th belong to the phase of “constraint”, the 10th belongs to the phase of “in-action” and the 17th, 22nd belong to the phase of “release”. We take the optical flow of the three phases in ROI1 (right lip corner) as an example
2.4 MHOOF特征提取与识别
考虑到微表情发生强度非常低的特点,即使在峰值帧,也很难用传统的静态特征进行识别,所以本文提取微表情序列的动态光流特征,此外,高速摄像机记录的微表情序列,帧与帧之间变化非常微弱,这样每个ROI内的主方向(包含像素点最多的光流方向区间)相较于其他方向不明显,容易被其他方向干扰,所以我们提取每一帧和第一帧之间的光流[Vx,Vy],然后将欧氏坐标转换成极坐标(ρ,θ),并将光流方向划分成图3所示的8个方向区间,最后计算13个ROIs内的HOOF特征。图5(a)、(b)分别展示了一个类别为高兴的微表情序列的三个阶段中每一帧和第一帧之间光流场和光流方向直方图,和图4(b)、(c)相比,最大的区别在于“正在发生”阶段和“结束”阶段,在图4(b)中,三个阶段的光流主方向分别是上升、平稳和下降,而在图5(a)中,三个阶段的光流主方向都为上升。同时在图5(b)中每个ROI内的主方向相较于其他方向更为明显,从而可以更好地反映微表情的变化。计算得到13个ROIs内的HOOF特征后,则一帧的HOOF特征Øi可由如下所得:
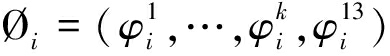
(12)
其中![]() 表示的是第k个ROI内第i帧和第一帧之间的HOOF特征,Øi是一个1
表示的是第k个ROI内第i帧和第一帧之间的HOOF特征,Øi是一个1![]() 8=104维的向量。
8=104维的向量。
接下来我们提取从起始帧到峰值帧的微表情序列的HOOF特征Øi,由于每个微表情序列的帧数不同,因此我们采用池化方法对HOOF特征Øi进行归一化,池化不仅可降低特征维数也可引入不变性,常用策略有平均池化(mean pooling)、最大池化(max pooling)和中值池化(median pooling),考虑到平均池化可以更好地表示微表情变化过程和消除极值干扰,并在实验对比之后,所提算法最终采用效果最佳的平均池化。因此,微表情序列的MHOOF特征Ω可由如下所得:
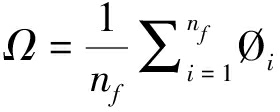
(13)
其中nf是当前微表情序列从起始帧到峰值帧的总帧数,Øi是帧fi的HOOF特征。MHOOF特征也是一个104维的向量。最后提取的MHOOF特征如图5(c)和图6(d)所示,图5(c)是类别为“高兴”微表情序列右嘴角区域ROI1的MHOOF特征,图6(d)是类别为“压抑”的微表情序列右嘴角区域ROI1的MHOOF特征。可以看到MHOOF特征很好地描述了这两类微表情“嘴角上扬”和“嘴角下降”的显著特征。
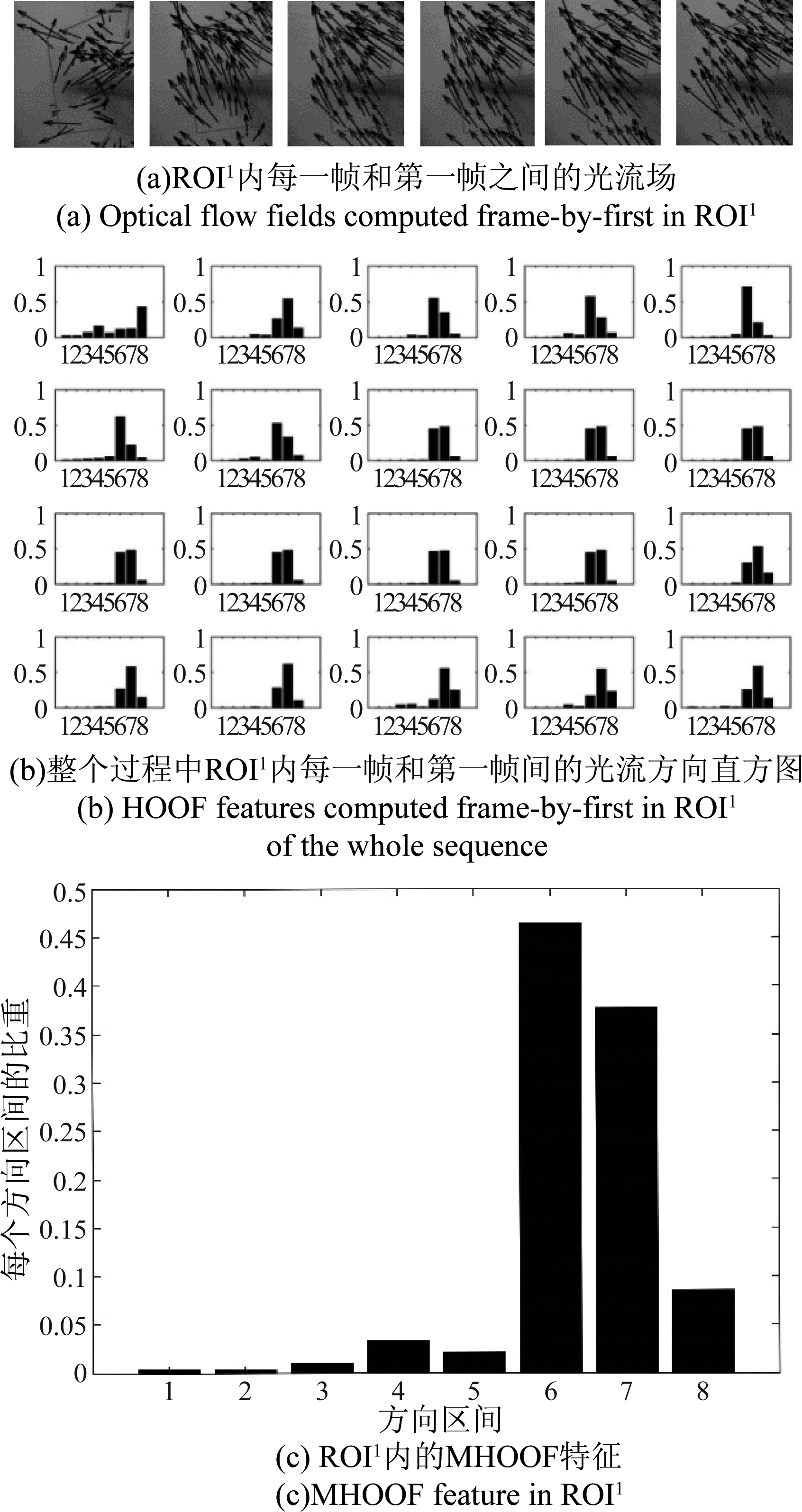
图5 (a)、(b)和图4中的(b)、(c)相对应,但ROI1内计算的是每一帧和第一帧之间的光流场和光流方向直方图,(c)是从起始帧到峰值帧ROI1内的MHOOF特征
Fig.5 (a) and (b) visualize the optical flow fields and HOOF features computed frame-by-first corresponding to Fig.4(b) and Fig.4(c), and (c) is the MHOOF feature in ROI1 extracted from onset frame to apex frame
提取到每个微表情序列的MHOOF特征后,选用适当的分类器进行识别。SVM(支持向量机)在解决小样本、非线性及高维模式识别中表现出许多特有的优势,目前微表情相关的数据库规模相对较小,因此本文采用SVM进行微表情识别。SVM通过核函数K(x,y)将数据映射到高维空间,并在高维空间构造判别函数来解决在原始空间中线性不可分的问题,常用的核函数如下:
(1)线性核函数(Linear Kernel):
K(x,y)=x·y+c
(2)多项式核函数(Polynomial Kernel):
K(x,y)=(γ*(x·y)+c)d
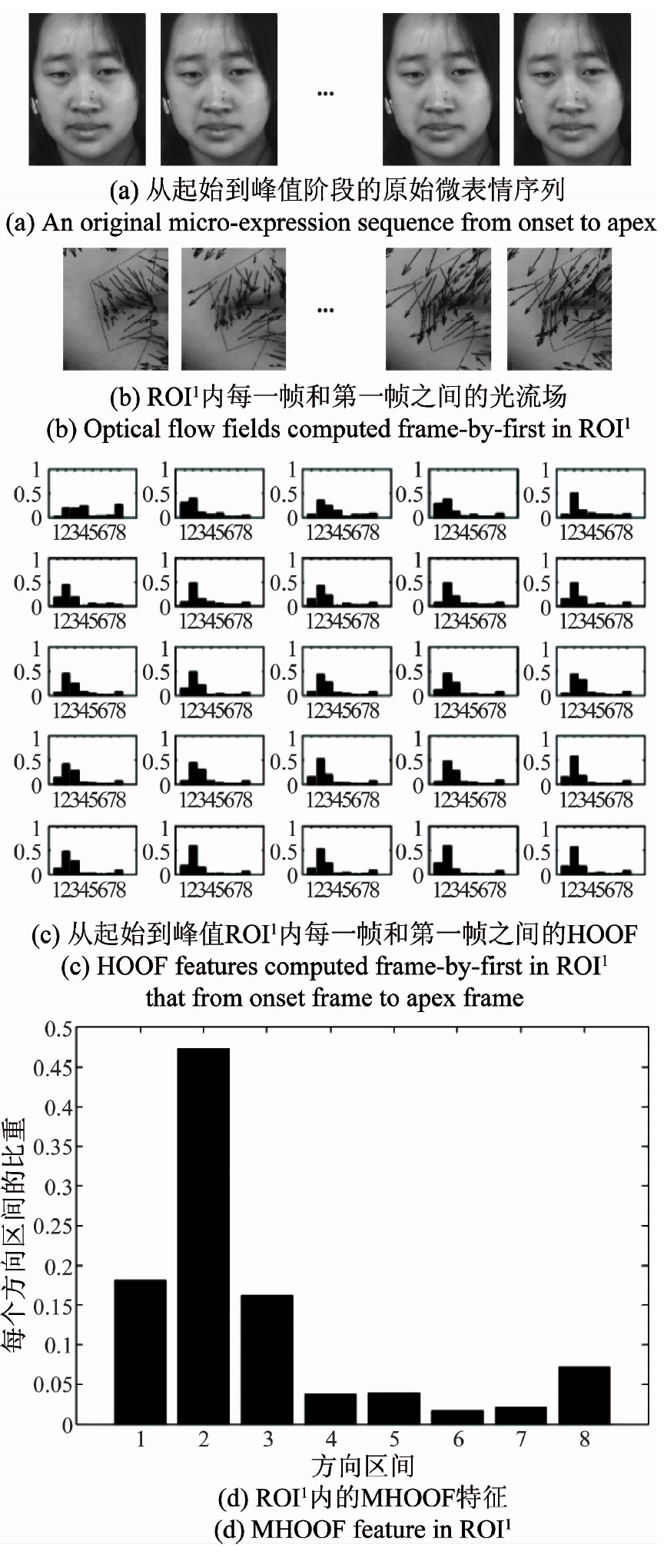
图6 类别为“压抑”的微表情从起始到峰值的光流变化。(a)是原始输入的图片序列,(b)和(c)是对应ROI1内的光流场和光流方向直方图,(d)是ROI1内的MHOOF特征
Fig.6 The optical flow of a micro-expression sequence from onset frame to apex frame labeled “repression”.(a) is the original input image sequence, (b) and (c) are the optical flow fields and HOOF in ROI1, and (d) is the MHOOF feature in ROI1
(3)径向基核函数(RBF Kernel):
K(x,y)=exp(-γ*‖x-y‖2)
(4)卡方核函数(Chi-Square Kernel):

本文采用LIBSVM[26]设置不同的核函数,并通过网格搜索法对惩罚参数c和核函数中的γ进行寻优。
3 实验和结果
为了验证MHOOF特征的有效性,我们在CASME II[23]微表情库上进行了实验,并和LBP-TOP[1]、MDMO[10]、STLBP-IP[4]、DiSTLBP-RIP[3]四种算法进行了对比。
3.1 数据集
CASME II数据库由中科院心理研究所负责维护的微表情库,和之前的CASME[24]数据库和SMIC[25]数据库相比,CASME II有如下两个优点可以更好的满足微表情研究的需要:
(1)CASME II有更高的时域分辨率和空间分辨率,其时域分辨率为200 fps,高于CASME的60 fps和SMIC的100 fps,同时,CASME II中人脸区域的面积大约为28![]() 340像素,也高于CASME中的19
340像素,也高于CASME中的19![]() 230像素和SMIC中的15
230像素和SMIC中的15![]() 190像素,更高的时空分辨率可以从持续时间短、发生强调低的微表情中提取到更多细节信息。
190像素,更高的时空分辨率可以从持续时间短、发生强调低的微表情中提取到更多细节信息。
(2)CASME II中增加了微表情发生的多样性,在CASME II采集过程中,一部分参与者在观看视频的过程中被要求始终保持中性状态,另外一部分则只有意识到有微表情要出现时才会抑制面部运动,而CASME和SMIC中只考虑了前一种,不同类型的微表情可能会有不同的动态特征。
基于上述特点,本文选用CASME II作为实验数据集,其中一共包含247个从26个参与者的将近3000个人脸运动中筛选出的微表情样本,每个微表情样本都标注了起始帧、峰值帧和结束帧,另外对动作单元和情感类别也都进行了标注。由于某些类别的样本数太少,所以通常将这247个样本的类别划分成四类[10]或五类[3- 4]:
四类:积极(32)、消极(25)、惊讶(64)、其他(126)。
五类:高兴(32)、惊讶(25)、厌恶(64)、压抑(27)、其他(99)。
3.2 算法对比
由于无论是划分成四类还是五类,每个类别的样本数都不均衡,所以我们采用留一验证法(Leave-One-Subject-Out, LOSO)[1,3-4,10]作为衡量标准。CASME II中共有26个对象,每一个对象都用作一次测试集,其余的作为训练集,26次之后,我们就会得到所有样本的预测值。由于算法MDMO和STLBP-IP、DiSTLBP-RIP分别是在四类划分和五类划分下进行实验的,所以本文对上述算法进行了重复,在四类和五类划分进行了统一比较。
LBP-TOP. 为了减少LBP-TOP的参数,我们将XY、XT、YT平面中邻域内的点数都设为4,X平面的半径Rx和Y平面的半径Ry设置为相等且从1到4,T平面的半径Rt设为从2到4,因为当T平面的半径设为1时,只能提取XY平面的空间特征而没有提取T平面的时域特征。四类划分下,当Rx=Ry=2,Rt=4且SVM的参数t=Linear Kernel,c=12.5时LBP-TOP达到的最好识别率是53.44%;五类划分下,当Rx=Ry=4,Rt=3且SVM的参数t=Linear Kernel,c=7.3时LBP-TOP达到的最好识别率是47.37%。
MDMO. 由于文献[10]中所用的DRMF人脸关键点检测算法在一些样本中不能正确检测出关键点,所以Liu等移除了这些样本,而我们在章节2.1中采用的算法可以很好地检测出每个样本的人脸关键点,所以我们首先使用该算法检测出每个微表情样本中第一帧的关键点,然后用Liu提供的源代码提取MDMO特征,最后对同样的247个样本进行实验。在四类划分下,当λ=0.75,SVM参数t=Linear Kernel,c=5.5时取得最好识别率为65.99%,在五类划分下,当λ=0.84,SVM参数t=Linear Kernel,c=6.1时取得最好识别率为58.30%。
STLBP-IP. 对于STLBP-IP算法,提取纹理特征1DLBP的掩码大小W,提取差分图像运动特征LBPS,R的半径R和邻域内的点数N,以及时域归一化长度T决定了最后的识别率,其中各参数取值为W={3,5,7,9},R={1,2,3},N={4,8},T=[5,60]。我们按文献[4]中的预处理方法将人脸对齐后裁剪到30![]() 257像素,然后将人脸区域划分成
257像素,然后将人脸区域划分成![]() 9的子区域块。在五类划分下,引用文献[4]中的参数设置,当W=9,R=3,N=8,T=45,SVM参数t=Chi-Square Kernel时取得最好识别率为59.51%;在四类划分下,我们对该算法进行了重复,当W=7,R=3,N=8,T=50,SVM参数t=Linear Kernel,c=14.2时取得最好识别率为61.94%。
9的子区域块。在五类划分下,引用文献[4]中的参数设置,当W=9,R=3,N=8,T=45,SVM参数t=Chi-Square Kernel时取得最好识别率为59.51%;在四类划分下,我们对该算法进行了重复,当W=7,R=3,N=8,T=50,SVM参数t=Linear Kernel,c=14.2时取得最好识别率为61.94%。
DiSTLBP-RIP.在STLBP-IP特征的基础上,DiSTLBP-RIP采用RPCA方法提取微表情的细微运动来替换差分图像,并结合一种基于拉普拉斯的特征选择方法来增强类与类之间的区分性。除了STLBP先关的参数即:1DLBP的掩码大小W、LBPS,R的半径R以及时域归一化长度T,拉普拉斯特征选择的特征组数P也会影响识别率。文献[3]中证明时域归一化长度T并不会有助于提高CASME II的识别率,所以只考虑参数W、R、N以及P,其中各参数取值为W={3,5,7,9},R={1,2,3},N={4,8},P=[1,25]。我们根据文献[3]中的参数将人脸对齐后裁剪到30![]() 257像素,然后将人脸划分成
257像素,然后将人脸划分成![]() 1的子区域块。在五类划分下,引用文献[3]中的参数W=9,R=3,N=8,P=21,SVM参数t=Chi-Square Kernel,最好识别率为64.78%;在四类划分下,我们对该算法进行了重复,当W=9,R=3,N=8,P=18,SVM参数t=Linear Kernel,c=5.8时取得最好识别率为65.18%。
1的子区域块。在五类划分下,引用文献[3]中的参数W=9,R=3,N=8,P=21,SVM参数t=Chi-Square Kernel,最好识别率为64.78%;在四类划分下,我们对该算法进行了重复,当W=9,R=3,N=8,P=18,SVM参数t=Linear Kernel,c=5.8时取得最好识别率为65.18%。
MHOOF. 本文新提出的MHOOF算法主要和ROI划分方法和峰值帧检测相关,本文将人脸区域划分成13个ROIs,并采用我们之前工作[22]中的峰值帧检测方法,在四类划分下,当SVM参数t=Linear Kernel,c=5.9时取得的最好识别率为69.64%,在五类划分下,当SVM参数t=Linear Kernel,c=6.8时达到的最好识别率为66.80%。从表2和表3可以得到,和上述算法中四类划分和五类划分下识别率最好的MDMO和DiSTLBP-RIP相比,本文MHOOF的识别率分别提升了5.53%和3.12%。同时我们还对比了文献[10]中的ROI划分方法,将人脸区域划分成36个ROIs,然后在相同条件下重新对MHOOF特征进行了实验,在四类划分下和五类划分下的最好识别率为63.56%和61.13%。此外,我们还对三种池化方法进行了对比,最大池化(MaxHOOF)和中值池化(MedianHOOF)在四类划分下达到的最好识别率分别是65.59%(SVM参数t=Linear Kernel,c=4.1)和67.61%(SVM参数t=Linear Kernel,c=7.8),在五类划分下达到的最好识别率分别是61.94%(SVM参数t=Linear Kernel,c=11.4)和62.75%(SVM参数t=Linear Kernel,c=6.2),两者和平均池化相比识别率均有所下降,由此可见本文所提出的平均光流方向直方图特征可以更好地用于微表情识别。
表2 “四类”划分下,各算法识别结果的比较
(括号内为上述讨论的各个算法的相关参数)
Tab.2 Comparison of recognition results in the situation of ”four-class”, where the values in bracket mean the parameters discussed above
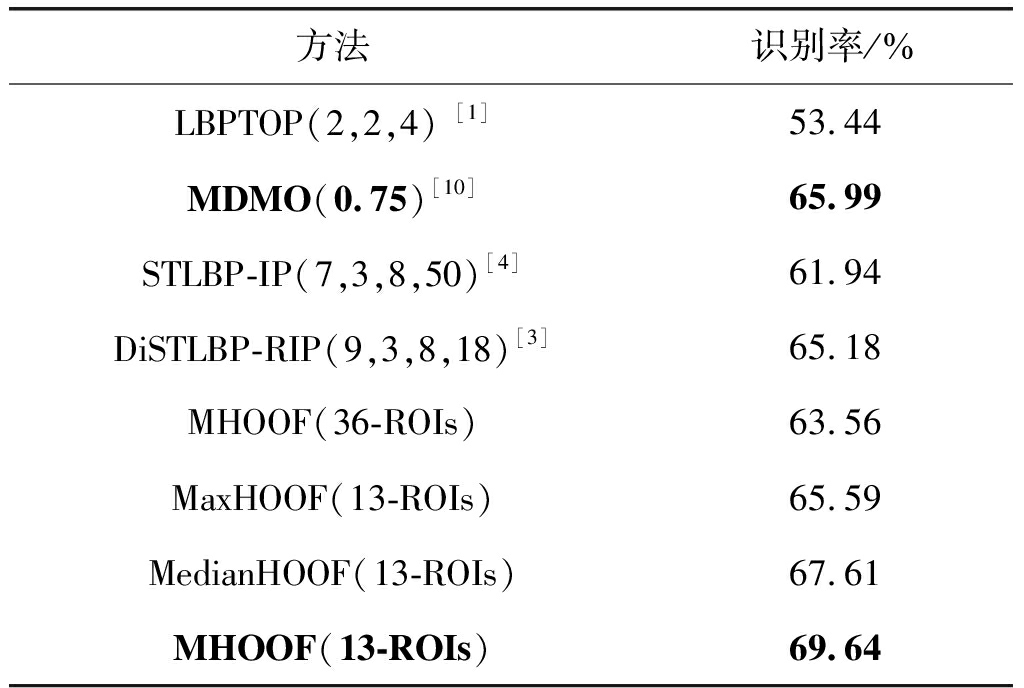
方法识别率/%LBPTOP(2,2,4) [1]53.44MDMO(0.75)[10]65.99STLBP-IP(7,3,8,50)[4]61.94DiSTLBP-RIP(9,3,8,18)[3]65.18MHOOF(36-ROIs)63.56MaxHOOF(13-ROIs)65.59MedianHOOF(13-ROIs)67.61MHOOF(13-ROIs)69.64
表3 “五类”划分下,各算法识别结果的比较
(括号内为上述讨论的各个算法的相关参数)
Tab.3 Comparison of recognition results in the situation of “five-class”, where the values in bracket mean the parameters discussed above
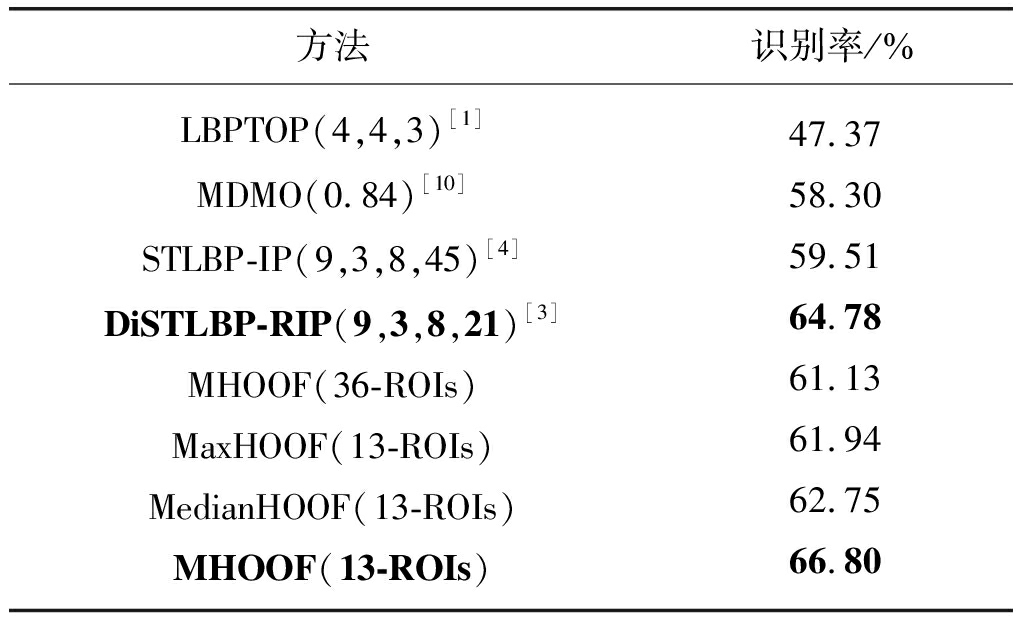
方法识别率/%LBPTOP(4,4,3)[1]MDMO(0.84)[10]STLBP-IP(9,3,8,45)[4]DiSTLBP-RIP(9,3,8,21)[3]MHOOF(36-ROIs)MaxHOOF(13-ROIs)MedianHOOF(13-ROIs)MHOOF(13-ROIs)47.3758.3059.5164.7861.1361.9462.7566.80
4 结论
本文提出了一种新的基于平均光流方向直方图(MHOOF)的微表情识别算法,首先,准确检测出人脸稠密关键点并对人脸区域进行ROI划分,区别于已有算法,所提算法通过提取特定ROI内相邻两帧之间的HOOF特征来检测微表情序列的峰值帧,然后提取从起始帧到峰值帧这一段图片序列的MHOOF特征进行表情识别。微表情库CASME II上的实验表明,从起始帧到峰值帧这一阶段的MHOOF特征与之前提出的LBP-TOP、MDMO、STLBP-IP和DiSTLBP-RIP相比,可有效描述微表情的变化并提高识别准确度。由于MHOOF特征依赖于第一帧为表情发生的起始帧,同时对峰值帧检测的准确性也有一定依赖,所以在今后的工作中,我们将进一步解决这些限制条件,并提高对光照和噪声的鲁棒性。
参考文献
[1] Zhao G, Pietikinen M. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2007, 29(6):915-928.
[2] Pfister T, Zhao G, Pietikainen M. Recognising spontaneous facial micro-expressions[C]∥International Conference on Computer Vision. IEEE Computer Society, 2011:1449-1456.
[3] Huang Xiaohua, Wang Sujing, Liu Xin, et al. Discriminative Spatiotemporal Local Binary Pattern with Revisited Integral Projection for Spontaneous Facial Micro-Expression Recognition[J]. IEEE Transactions on Affective Computing, 2017, PP(99):1-1.
[4] Huang X, Wang S J, Zhao G, et al. Facial Micro-Expression Recognition Using Spatiotemporal Local Binary Pattern with Integral Projection[C]∥IEEE International Conference on Computer Vision Workshop. IEEE Computer Society, 2015:1-9.
[5] Ganesh A, Ma Y, Rao S, et al. Robust Principal Component Analysis: Exact Recovery of Corrupted Low-Rank Matrices via Convex Optimization[J]. Journal of the Acm, 2009, 58(3):11.
[6] Polikovsky S, Kameda Y, Ohta Y. Facial micro-expressions recognition using high speed camera and 3D-gradient descriptor[C]∥International Conference on Crime Detection and Prevention. IET, 2009:1- 6.
[7] 柳晶晶, 陶华伟, 罗琳,等. 梯度直方图和光流特征融合的视频图像异常行为检测算法[J]. 信号处理, 2016, 32(1):1-7.
Liu Jingjing, Tao Huawei, Luo Lin, et al. Video Anomaly Detection Algorithm Combined with Histogram of Oriented Gradients and Optical Flow[J]. Journal of Signal Processing, 2016, 32(1): 1-7. (in Chinese)
[8] 岑翼刚, 王文强, 李昂,等. 显著性光流直方图字典表示的群体异常事件检测[J]. 信号处理, 2017, 33(3):330-337.
Cen Yigang, Wang Wenqiang, Li Ang, et al. Dictionary Representation for Group Anomaly Event Detection Based on the Histograms of Salience Optical Flow[J]. Journal of Signal Processing, 2017, 33(3): 330-337. (in Chinese)
[9] Li Xiaohong, Yu Jun, Zhan Shu. Spontaneous facial micro-expression detection based on deep learning[C]∥Signal Processing (ICSP), 2016 IEEE 13th International Conference on. IEEE, 2017:1130-1134.
[10] Liu Y J, Zhang J K, Yan W J, et al. A Main Directional Mean Optical Flow Feature for Spontaneous Micro-Expression Recognition[J]. IEEE Transactions on Affective Computing, 2016, 7(4):299-310.
[11] Maryam Asadi-Aghbolaghi, Albert Clapes, Marco Bellantonio, et al. A Survey on Deep Learning Based Approaches for Action and Gesture Recognition in Image Sequences[C]∥Automatic Face & Gesture Recognition (FG 2017), 2017 12th IEEE International Conference on. IEEE, 2017: 476- 483.
[12] Sun Y, Wang X, Tang X. Hybrid Deep Learning for Face Verification[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(10):1997-2009.
[13] Li Huibin, Sun Jian, Xu Zongben, et al. Multimodal 2D+3D Facial Expression Recognition with Deep Fusion Convolutional Neural Network[J]. IEEE Transactions on Multimedia, 2017, PP(99):1-1.
[14] Patel Devangini, Hong Xiaopeng, Zhao Guoying. Selective Deep Features for Micro-Expression Recognition[C]∥Pattern Recognition (ICPR), 2016 23rd International Conference on. IEEE, 2016:2258-2263.
[15] Tadas Baltrušaitis, Peter Robinson, Louis-Philippe Morency. OpenFace: An open source facial behavior analysis toolkit[C]∥Applications of Computer Vision (WACV), 2016 IEEE Winter Conference on. IEEE, 2016:1-10.
[16] Baltrusaitis T, Robinson P, Morency L P. Constrained Local Neural Fields for Robust Facial Landmark Detection in the Wild[C]∥IEEE International Conference on Computer Vision Workshops. IEEE Computer Society, 2013:354-361.
[17] Morency L, Baltrusaitis T, Robinson P. 3D Constrained Local Model for rigid and non-rigid facial tracking[C]∥Computer Vision and Pattern Recognition. IEEE, 2012:2610-2617.
[18] Asthana A, Zafeiriou S, Cheng S, et al. Robust Discriminative Response Map Fitting with Constrained Local Models[C]∥IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2013:3444-3451.
[19] Liong S T, See J, Wong K S, et al. Automatic apex frame spotting in micro-expression database[C]∥Pattern Recognition (ACPR), 2015 3rd IAPR Asian Conference on. IEEE, 2015:665- 669.
[20] Lucas B D, Kanade T. An iterative image registration technique with an application to stereo vision[C]∥International Joint Conference on Artificial Intelligence. Morgan Kaufmann Publishers Inc. 1981:674- 679.
[21] Bouguet J Y. Pyramidal implementation of the Lucas Kanade feature tracker description of the algorithm[J]. Opencv Documents, 1999, 22(2):363-381.
[22] Ma H Y, An G Y. A region histogram of oriented optical flow feature for apex frame spotting in micro-expression[C]∥IEEE International Symposium on Intelligent Signal Processing and Communication Systems. IEEE, 2017.
[23] Yan W J, Li X, Wang S J, et al. CASME II: An Improved Spontaneous Micro-Expression Database and the Baseline Evaluation[J]. Plos One, 2014, 9(1):1- 8.
[24] Yan W J, Wu Q, Liu Y J, et al. CASME database: A dataset of spontaneous micro-expressions collected from neutralized faces[C]∥IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. IEEE, 2013:1-7.
[25] Li X, Pfister T, Huang X, et al. A Spontaneous Micro-expression Database: Inducement, collection and baseline[C]∥IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. IEEE, 2013:1- 6.
[26] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. Acm Transactions on Intelligent Systems & Technology, 2011, 2(3):1-27.


