1 引言
由于通信辐射源个体的差异,在信号的表现形式上不可避免地存在着不影响信息传递的细微特征差异,这些可检测、可重现差异的细微特征称为信号细微特征或通信辐射源指纹特征(Communication Transmitter Fingerprint,CTF)[1]。在军事应用上,由于当前战场电磁环境中充斥各类电磁信号,使得电磁环境纷繁多变,而识别敌方通信辐射源个体对于我方掌握战场制信息权至关重要。因此通过准确提取CTF特征,快速有效地识别不同通信辐射源个体,可以为指挥员判定辐射源的基本性质、分析通信网络结构、确定敌威胁等级和电子干扰对象提供重要的决策依据[2]。在民用领域中,CTF特征可以用于准确判别通信电台对电磁频谱的使用情况,及时发现非法通信电台等。
近年来,国内外对CTF特征的研究越发深入,主要分为两类:信号暂态特征提取方法和信号稳态特征提取方法。前一种方法主要是早期研究成果,其对瞬态特征的完整性要求很高,而由于瞬态特征与噪声相似,又在信号截获、特征提取的过程中增加了出错概率,因此目前已很少采用。后一种方法对信号的稳态特征进行变换、提取,可以达到准确提取信号指纹特征的目的,应用范围广泛。文献[3]提出了一种基于双谱特征融合的CTF特征识别方法,可以实现快速准确的CTF特征提取并分类识别,但对训练样本数量要求较高。文献[4]基于信号频率跳变时刻的瞬时包络特征计算分形维数,提取的CTF特征的多分类性能只限于3部电台。文献[5]提出利用经验模态分解的方法提取CTF特征,在噪声较大的环境下识别率仍不理想。
尽管上述方法在一些理想条件下取得了令人满意的识别结果,但在实际复杂的电磁环境条件下,尤其是战时,对于每个电磁环境辐射源而言,人们很难获取充裕的已知类别的辐射源观测样本数据,即在实际复杂电磁环境下,我们常常面临的是小样本条件下电磁环境辐射源细微特征提取问题,所谓的“小样本”问题,即用于指导模型训练的有标签样本数量有限,不足以充分训练特征提取模型,从而导致提取的CTF特征不能良好表征通信辐射源个体。显然,如果直接采用上述提出的基于充分样本的流形学习方法,其性能必将受到严重影响。
“深度学习”(Deep Learning)这一术语是在2006年由机器学习领域的领军人物Hinton和他的学生Salakhutdinov在著名学术刊物《Science》上发表的学术论文中首次提出的[9]。所谓深度学习是指通过组合低层特征形成更加抽象的高层表示(属性类别或特征),以发现数据的分布式特征表示[13]。近年来,深度学习[6-12]在信号处理领域应用广泛,处理的对象包括图像、语音以及文本等。在图像方面,Hinton[7]提出采用深度神经网络对图像信号进行降维处理,实现准确识别;Ouyang[8]在2013年提出利用深度卷积神经网络识别视频信号中的行人;语音信号方面,马勇[9]在稀疏自编码网络中引入dropout技术对说话人进行准确分割;Kenny P[10]等将语音信号投影到说话人子空间和信道子空间提取说话人因子特征,提高了说话人的识别技术;文本数据方面,彭君睿[11]通过堆栈去噪自编码器对文本数据进行情感分类,实现了跨域学习。针对实际复杂电磁环境下通信辐射源个体识别问题,本文拟引入深度学习理论,提出一种基于堆栈自编码器[11]的通信辐射源指纹特征提取方法。首先通过预处理(高阶谱分析)将原始通信辐射源信号从时域转化到高维特征空间,然后利用大量无标签的通信辐射源高维样本训练堆栈自编码器网络,在此基础上,通过少量有标签的通信辐射源样本对模型进行精校,从而有效挖掘“小样本”条件下通信辐射源观测样本的深层细微特征。
2 基于深度学习的通信辐射源指纹特征提取的可行性分析
对于通信辐射源指纹特征的研究,一般来说分为两类:暂态特征分析和稳态特征分析。前者在表现形式上有着非常显著的差异,可以很好地作为指纹特征反映辐射源个体情况,然而在实际战场电磁环境中,电磁信号密集、复杂、交错而多变,信号的传输时间短,变化较为剧烈,导致信号暂态特征提取尤为困难,并且该方法还存在难以识别相同型号、相同工作模式的通信辐射源个体等问题,实用效果不佳。后者主要集中研究由通信辐射源内部各元器件的不稳定性、性能参数的非线性、元器件加工工艺缺陷所造成的各类稳态特征,利用通信辐射源信号的调制参数、瞬时特性、分形特征、杂散特征以及高阶统计特征等作为指纹特征,用于表征通信辐射源的个体差异。然而,此类方法存在以下几点局限性,导致其在实际应用中无法达到理论所述的性能标准:(1)实际战场电磁环境中的通信电台通常组网进行工作,其型号、工作模式通常是相同的,通过调制参数上的差异无法准确表征不同的电台个体;(2)“小样本”问题无法很好地解决,即可供采集用于训练指纹特征学习机的已知样本数目相对有限;(3)将信号中微弱的杂散特征成分作为指纹特征,在实际环境中极易受到噪声或电子干扰而影响其表征通信辐射源个体的能力;(4)高阶谱特征往往处于高维特征空间,尽管可以较好地避免周围环境的干扰,但是由于其高维特性,通用的分类器难以从中充分学习,导致分类识别性能下降。由此可见,人为设计指纹特征总是很难完整反映特定型号、调制样式的通信辐射源信号的细微差异,若是能够跨越这一阶段,直接由信号本身中提取指纹,则可以大大加强指纹特征的表征能力。
深度学习应用到通信辐射源指纹特征提取中,有以下几个特点使其优于传统方法:(1)无监督学习策略使其直接从输入的数据中提取指纹特征,跨越了人工设计指纹特征的阶段,节省了大量科研成本;(2)相比于有限的已知样本,深度学习方法可以很好地利用实际复杂电磁环境中的海量无标签通信辐射源样本,充分训练学习机模型,更好表征通信辐射源个体,有效改善“小样本”问题对指纹特征提取的影响;(3)以逐层贪婪的方式对数据特征压缩,可使最终提取的指纹特征具备较低的维度,在以较低维度特征有效表征通信辐射源个体的同时,还可与传统分类器对接通用,解决通用分类器不能完整利用指纹特征信息的问题。
文献[12]将深度学习理论中的深度限制玻尔兹曼机用于雷达辐射源的特征提取,该方法在低信噪比环境下,对于不同类型的雷达辐射源特征有着较高的表征能力与较好的鲁棒性,证明了深度学习理论在信号特征提取上应用的可实现性。在此基础上,本文引入堆栈自编码器(Stacked Auto-Encoder,SAE)算法用于提取“小样本”条件下相同类型、相同工作状态的通信辐射源指纹特征,获得在“小样本”条件下超越传统方法的辐射源个体表征能力,并在实际复杂电磁环境中保持较强的鲁棒性,为将辐射源指纹特征广泛用于如电子对抗侦察等军事领域提供可靠的技术支持。
3 基于SAE的通信辐射源指纹特征提取
首先将接收机采集的通信辐射源信号进行去噪、高阶谱变换等预处理,然后算法对处理后的通信辐射源信号矩形积分双谱进行CTF特征提取。按照图1算法流程,首先利用信号中的无标签数据通过无监督预训练提取模型初始参数,然后在有监督精校阶段辅助模型利用有标签数据训练模型的有监督参数,通过多次迭代计算模型的最优参数,输出CTF特征。
图1 本文算法流程
Fig.1 Procedure of algorithm proposed
3.1 无监督预训练
在提取CTF特征时采用无监督学习方法的主要原因是:(1)自编码器进行无监督学习训练模型,不依赖先验知识和已知标签的样本;(2)在实际复杂电磁环境中存在着海量的无标签通信辐射源信号样本,利于使用无监督学习进行回归。在CTF特征提取任务中,通过大量无标签样本训练模型,使梯度能够达到全局最优点,达到理想的特征提取效果。故在本算法中,首先将大量无标签样本用于SAE预训练,针对通信辐射源信号SIB特征初始化模型。
本文采用的SAE[11]的基本单元是自编码器,其基本结构如图2所示,通过维度小于输入层的隐藏层表达高维输入,并在解码器中根据低维表达重构高维输入,借助梯度下降的迭代优化方法,输出重构误差最小的无监督模型参数。具体过程说明如下。
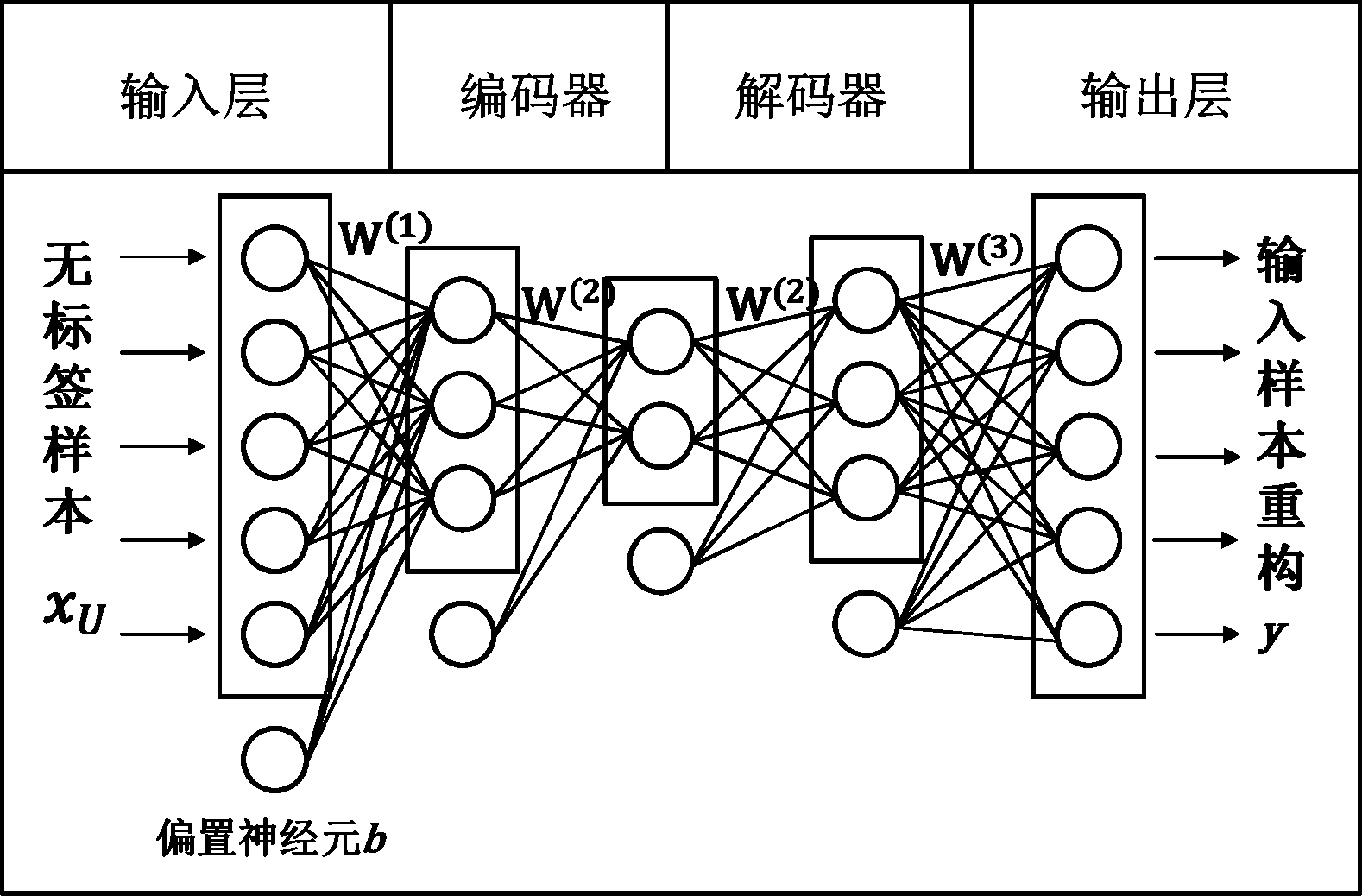
图2 隐藏层数为2的SAE基本结构
Fig.2 Basic structure of SAE with two hidden layers
设无标签通信辐射源信号是高维特征样本xU,样本共m个,特征维度是n。自编码器单元对xU的表达函数为:
hW,b(xU)=WxU+b
(1)
其中W是自编码器隐藏层神经元的权重系数矢量,b是偏置。
此外,每个神经元对输入特征会进行非线性激励,激励函数为:
a(xU)=sigmoid(xU)
(2)
若将多个自编码器单元连接起来,前一个自编码器单元的隐层作为后一个自编码器单元的输入层,那么就是本文所用SAE。假设SAE的隐层数目为2(本文实验所用SAE隐层数正是2),那么高维输入记为h(0),第一层表达记为h(1),非线性激励记为a(1),第二层表达为:h(2)=W(2)h(1)+b(2),第二层的非线性激励为:a(2)=sigmoid(h(1))。
解码器首层表达则为:
h(3)=W(2)h(2)+b(2)
(3)
计算解码器端对高维输入的重构y:
y=h(4)=W(1)h(3)=b(1)
(4)
将重构y与高维输入h(0)之间的均方误差定义为重构误差,可以构造代价函数J(W,b):
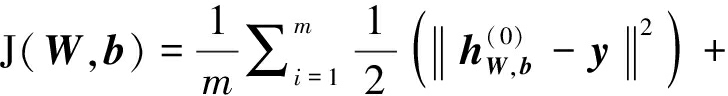
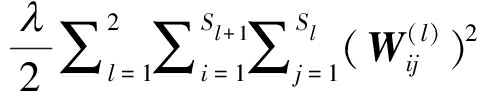
(5)
上式第一项是重构误差项,表示重构y与高维输入![]() 之间的差异大小;第二项是权重衰减项,控制代价函数中权重的大小,避免出现过拟合现象,其中λ是权重衰减因子,sl+1表示第l+1层的神经元数目,sl表示当前第l层的神经元数目,
之间的差异大小;第二项是权重衰减项,控制代价函数中权重的大小,避免出现过拟合现象,其中λ是权重衰减因子,sl+1表示第l+1层的神经元数目,sl表示当前第l层的神经元数目,![]() 表示第l层与第l+1层的神经元传播路径的权重。
表示第l层与第l+1层的神经元传播路径的权重。
预训练的目的是通过迭代计算找到代价函数J(W,b)的最小值,由反向传播算法实现。可由输出层的非线性激励a(4)=sigmoid(h(3)),计算输出层残差矢量δ(4):δ(4)=-(h(0)-a(4))f ′(h(4)),式中的![]()
然后就可以递推计算隐藏层第l层(l=1,2,3)的残差矢量δ(l):
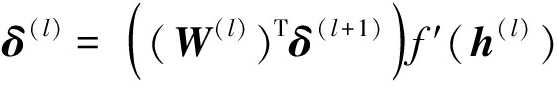
(6)
由反向传播算法,可以得知第l层的权重与偏置矢量的梯度下降方向矢量分别为:
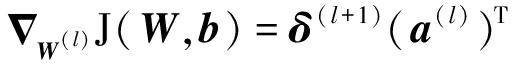
(7)
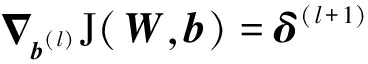
(8)
最后给出模型参数的更新公式(式中的α为学习率):
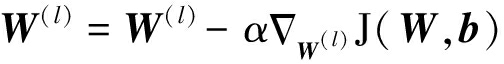
(9)
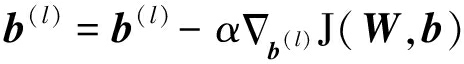
(10)
当迭代计算使代价函数收敛至最小时,输出模型参数W=(W(1),W(2))和b=(b(1),b(2))作为初始化参数θinitial。
3.2 有监督精校
有监督精校,是利用已知样本所属通信辐射源个体的信号数据对算法的训练参数再进行训练,使训练参数对输入的SIB特征拟合程度更优,最终提取的CTF特征因而可以准确区分不同通信辐射源个体,满足指纹特征的要求。由于有标签样本数量有限,若用于整个SAE模型的训练,出现梯度弥散、梯度停滞等问题的概率较大,而只在softmax回归模型中进行训练,一则可以发挥有监督学习的特点,使模型与训练集的拟合程度更高;二则可以降低获取训练集的代价,深度挖掘存在于有标签样本中的通信辐射源个体信息,准确提取CTF特征。
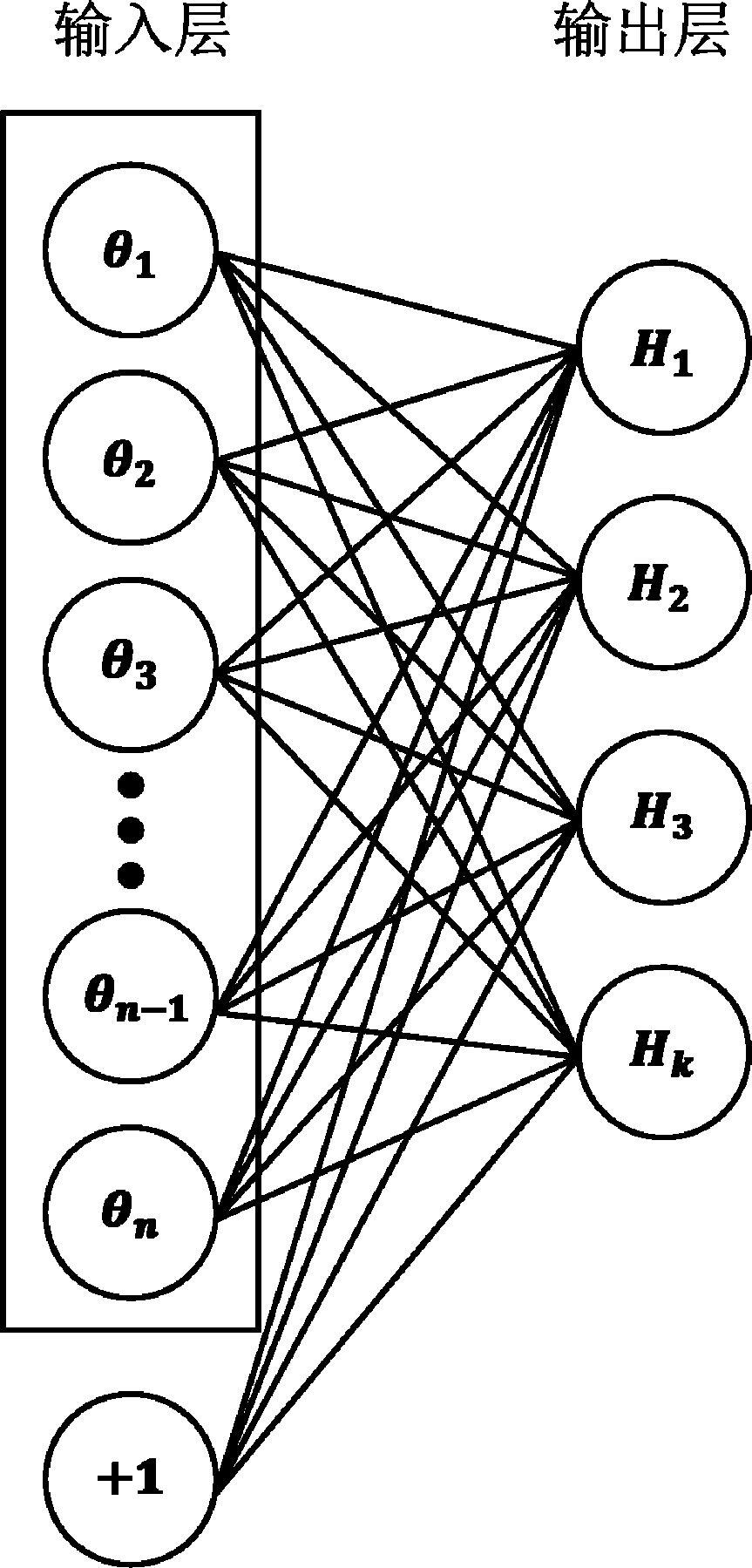
图3 softmax回归模型结构
Fig.3 Structure of softmax regression model
有监督精校利用SAE中提取的初始化参数θinitial对softmax回归模型参数进行初始化,该模型结构如图3所示,与SAE结构相似,只是没有隐藏层。它输出的不再是对输入的重构,而是对输入样本所属类别的估计。
设有标签通信辐射源信号是高维特征样本xL,样本共M个,特征维度是n+1,标签是一个M维且元素均为类别标号取值k的列矢量,在xL的最后一列,k是通信辐射源个体的编号。softmax回归模型会根据模型参数θ对输入的每个样本所属通信辐射源个体类别进行估计,通过分类概率p(yi=j|xL)(其中i=1,2,...,M, j=1,2,...,k)表示。现用一个假设函数H(xL)对所有有标签通信辐射源信号的分类概率进行表达:
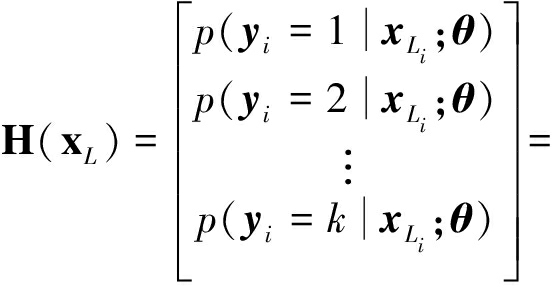
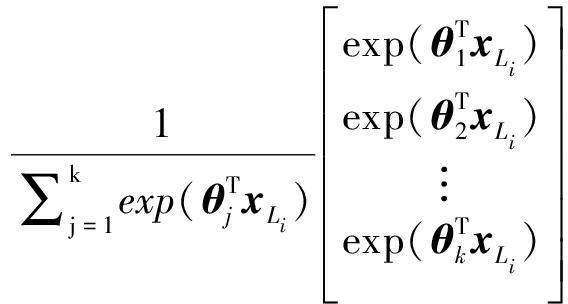
其中θ是softmax的模型参数,由θinitial初始化,是一个sL×n维的矩阵(sL表示SAE第L层的神经元数目),由隐藏层各层所有权重系数矩阵相乘得到(本文算法中编码器隐藏层数为2):
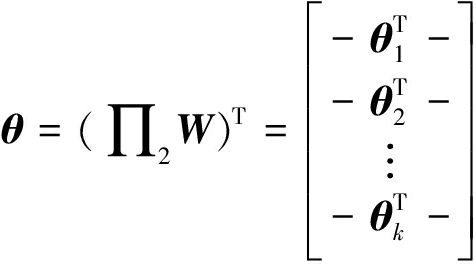
(11)
另外,![]() 是归一化因子,可令所有分类概率之和为1。
是归一化因子,可令所有分类概率之和为1。
为通过训练使再模型参数θ拟合有标签通信辐射源样本,定义代价函数JL(θ),作为有监督训练的目标函数:

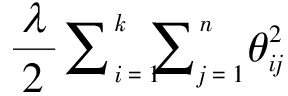
(12)
在上式中,第一项是样本正确分类概率分布,M是输入有标签通信辐射源数据的数目,k是通信辐射源个体类别数目;示性函数1{yi=j}在yi=j时(j=1,...,k)为1,其余时候为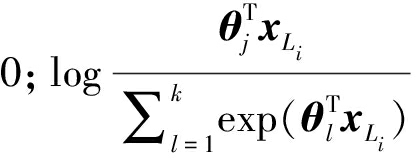 表示分类概率的对数值;第二项是权重衰减项,使代价函数为严格凸函数,λ是权重衰减因子,n是样本xL中表示数据特征部分的维度大小,也是softmax模型参数θ的维度,θij为第i类第j个样本对应的模型参数。
表示分类概率的对数值;第二项是权重衰减项,使代价函数为严格凸函数,λ是权重衰减因子,n是样本xL中表示数据特征部分的维度大小,也是softmax模型参数θ的维度,θij为第i类第j个样本对应的模型参数。
由于代价函数JL(θ)为严格凸函数,故只能通过迭代运算方法进行计算,此处采用与SAE相同的反向传播算法,首先计算代价函数的梯度![]()
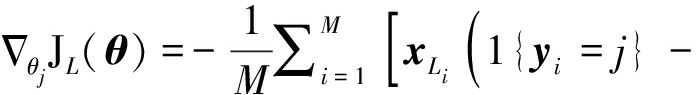
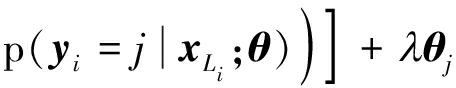
(13)
模型参数θ的更新公式为:
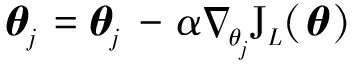
(14)
当迭代计算使代价函数JL(θ)收敛至最小时,输出模型参数θopt,此即为算法提取的通信辐射源指纹特征。
3.3 算法步骤
根据本章3.1和3.2节的算法原理推导,将主要步骤总结如下:
步骤1 输入无标签通信辐射源数据xU,在SAE中进行无监督预训练。
根据公式(1)对输入数据进行编码,可得SAE各层对输入数据的非线性表达h(l)。
步骤2 构造无监督训练代价函数。通过联立公式(3)(4)可得重构y,并据此计算公式(5)所示代价函数J(W,b)。
步骤3 对无监督代价函数进行迭代优化计算。根据公式(9)(10)参数更新方法,当无监督代价函数取得最小值时,可以得到有监督过程的初始化参数θinitial。
步骤4 构造有监督代价函数。用θinitial对softmax回归模型参数进行初始化,依据公式(11)(12)计算有监督代价函数JL(θ)。
步骤5 迭代计算有监督代价函数JL(θ)的最小值。由公式(13)(14)可计算模型参数θ的最优值θopt,作为CTF特征输出。
4 实验结果与分析
4.1 实验设置
为了评估基于深度学习的通信辐射源指纹特征提取算法的可行性和有效性,本节在kenwood手持式FM电台数据集和kirisun通信电台数据集上进行了大量实验。为更好地分析实验结果,将提出的算法(SAE/CTF)与传统的基于杂散特征(R特征)提取方法[14]、基于SIB特征的高阶统计量方法[3]进行了实验比较。
本节设置的两组实验,第一组为在kenwood通信电台数据集和kirisun通信电台数据集上分别进行的分类识别实验,主要验证了基于深度学习的通信辐射源指纹特征提取算法在训练样本个数不同的情况下,对相同型号、工作状态的不同通信辐射源个体所提取的指纹特征能够反映个体差异的可行性;第二组为不同辐射源个体的识别差异实验,主要验证了基于深度学习的通信辐射源指纹特征提取算法在“小样本”条件下对kenwood通信电台数据集中不同辐射源个体指纹特征提取的有效性。
实验所采用的kenwood通信电台数据集,是在实际环境下采集的5部相同型号、工作状态的kenwood手持式FM通信电台的通信信号,信号带宽为25 kHz,接收机带宽为100 kHz,采样频率为204.8 kHz,采样点数为1023658个,采样数据为零中频I/Q正交信号。kirisun通信电台数据集的采集,5部kirisun手持式FM电台带宽为25 kHz,接收机将截获信号经正交混频和A/D转换,输出零中频I/Q双路正交信号,接收机采集增益为6 dB,信道带宽100 kHz,采样率为312.5 kHz,每个样本的采样时长均为30 s。
对通信辐射源信号进行矩形积分双谱变换(Square Integral Bispectra,SIB)后可获得包含CTF特征的高维数据,将其输入SAE进行训练,可以保证从中提取的指纹特征能够准确表征辐射源个体。同时,考虑到硬件性能与运算效率,最终选取4096维SIB特征作为高维输入样本。SAE的输入层节点与输入样本应为等维映射,因此输入层节点数目为4096。根据实验经验,设计层数为2,节点数分别为256和64的隐含层,构成结构为4096-256- 64的自编码器单元。由于SAE的解码部分将压缩后的CTF特征重构为输入样本,因此输出层节点数也为4096。
对于基于SIB特征的高阶统计量方法(SIB)和本文算法(SAE/CTF),采用的SIB特征维度也为4096维。为更好地比较实验组中各特征提取方法的性能,采用与有监督精校模型相同的softmax分类器,每组实验重复20次,取平均识别率作为最终识别结果,所有实验均在一台CPU为Intel Core i7- 4720HQ 2.6GHz的笔记本电脑上运行。
4.2 算法整体识别性能
为了验证基于深度学习的通信辐射源指纹特征提取算法在不同“小样本”条件下提取的CTF特征可以反映通信辐射源个体之间的细微差异,在kenwood通信电台数据集和kirisun通信电台数据集上分别进行分类识别实验,并将相同实验条件下的实验结果与R特征、SIB方法进行比较。
将5部kenwood通信电台的150000个样本,分别从每个通信电台个体中随机选取15000,30000,45000,60000,75000个有标签样本构成有标签训练样本集,其余60000个作为无标签样本构成无标签训练样本集,再从每个通信电台个体最终剩余的样本中随机选择1500个样本作为测试样本集,得到5个实验变量组,记为E1,E2,E3,E4,E5;将5部kirisun通信电台的45000个样本,分别从每个通信电台个体中随机选取4500,9000,13500,18000,27500个有标签样本构成有标签训练样本集,其余18000个作为无标签样本构成无标签训练样本集,再从每个通信电台个体最终剩余的样本中随机选择450个样本作为测试样本集,得到5个实验变量组,记为E6,E7,E8,E9,E10。每个实验变量组独立重复20次,计算平均识别率。R特征、SIB和SAE/CTF方法在kenwood数据集和kirisun数据集上取不同有标签样本数时的识别性能如表1(a)、(b)所示。
表1(a) kenwood数据集上R特征、SIB和SAE/CTF取不同训练样本数时平均识别率
Tab.1(a) Average recognition rate of different training sample number taken by R feature, SIB and SAE/CTF method
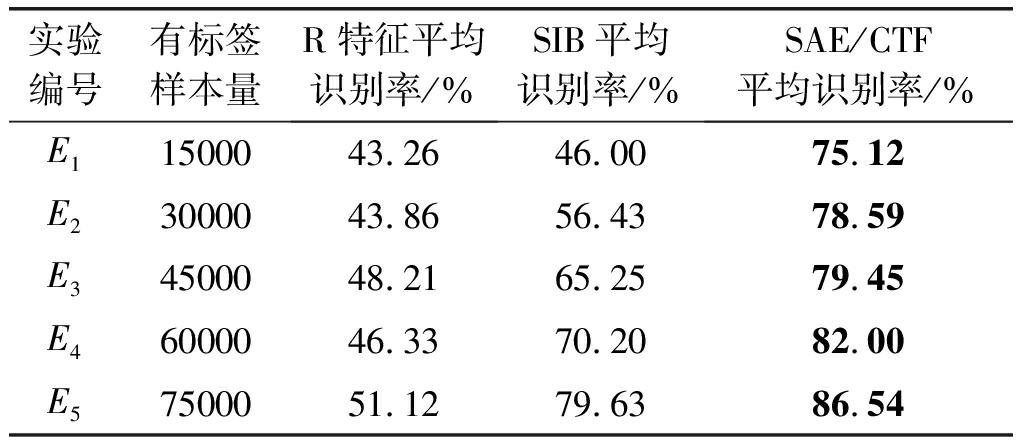
实验编号有标签样本量R特征平均识别率/%SIB平均识别率/%SAE/CTF平均识别率/%E11500043.2646.0075.12E23000043.8656.4378.59E34500048.2165.2579.45E46000046.3370.2082.00E57500051.1279.6386.54
表1(b) kirisun数据集上R特征、SIB和SAE/CTF取不同训练样本数时平均识别率
Tab.1(b) Average recognition rate of different training sample number on kirisun dataset by R feature, SIB and SAE/CTF method
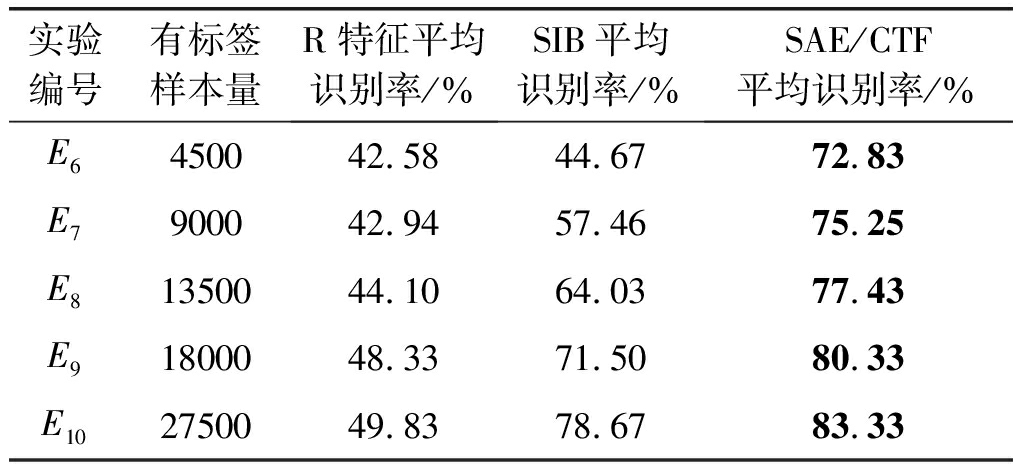
实验编号有标签样本量R特征平均识别率/%SIB平均识别率/%SAE/CTF平均识别率/%E6450042.5844.6772.83E7900042.9457.4675.25E81350044.1064.0377.43E91800048.3371.5080.33E102750049.8378.6783.33
从表1可以看出:(1)kenwood通信电台数据集的实验结果说明,在不同的“小样本”条件下,SAE/CTF方法均获得最优的分类识别性能,即该方法所提取的CTF特征能够准确表征通信辐射源个体,SIB方法次之,而R特征方法的识别效果最差;(2)E4中R特征方法的结果出现了异常的下降,这是由于杂散特征在实际环境中极为微弱,在“小样本”条件下进行特征提取易受干扰;(3)kirisun通信电台数据集对应的实验E6~E10显示,SAE/CTF识别率在小样本条件下显著优于对照算法,并且在有标签样本相对充足时,E9,E10,识别正确率超过80%,说明能够准确表征小样本条件下同类型通信电台的不同个体;(4)将kenwood通信电台数据集与kirisun通信电台数据集的实验结果进行对比可以发现,前三组实验的有标签样本量均少于无标签样本量,在此条件下传统方法如R特征法、SIB法对于同类型通信辐射源个体的识别能力较差,而本文提出的SAE/CTF方法能够大致将不同通信辐射源个体进行区分识别;(5)后两组实验中有标签样本量与无标签样本量相当或更为充足,对照算法的识别性能明显提高,但本文方法仍然能够表现出最优的识别性能,说明通过深度学习可以较好地结合有标签样本与无标签样本,并从中提取能够有效表征多个不同通信辐射源个体的指纹特征。
4.3 不同辐射源个体特征识别实验
为了验证基于深度学习的通信辐射源指纹特征提取算法在同一“小样本”条件下提取的CTF特征可以反映不同通信辐射源之间的个体差异,在kenwood通信电台数据集上进行分类识别实验,并将相同实验条件下的实验结果与R特征、SIB方法进行比较。
在4.2节实验变量组E5的“小样本”条件下,将5部kenwood通信电台样本,按照该节样本划分方法,分为![]() 每个实验变量组独立重复20次,计算平均识别率。R特征、SIB和SAE/CTF方法在数据集上取对不同kenwood通信电台个体的识别率如表2所示。
每个实验变量组独立重复20次,计算平均识别率。R特征、SIB和SAE/CTF方法在数据集上取对不同kenwood通信电台个体的识别率如表2所示。
从表2可以看出:在该“小样本”条件下,SAE/CTF方法在单部电台的识别性能上也超过R特征和SIB方法,与整体识别性能一致,说明该算法对5部电台均有效;![]() 实验组出现异常的识别性能偏低,可能与电台工作状态不稳定导致的无关干扰较大有关;SIB方法与SAE/CTF方法的识别结果相差不超过10%,不如整体识别性能实验中的差距大,是因为选用的实验组中有标签样本数目相对较充足,模型训练效果受训练样本数目的局限较小的缘故。
实验组出现异常的识别性能偏低,可能与电台工作状态不稳定导致的无关干扰较大有关;SIB方法与SAE/CTF方法的识别结果相差不超过10%,不如整体识别性能实验中的差距大,是因为选用的实验组中有标签样本数目相对较充足,模型训练效果受训练样本数目的局限较小的缘故。
表2 R特征、SIB和SAE/CTF方法对不同电台个体的识别结果
Tab.2 Identification result of individual radios by R feature, SIB, and SAE/CTF method
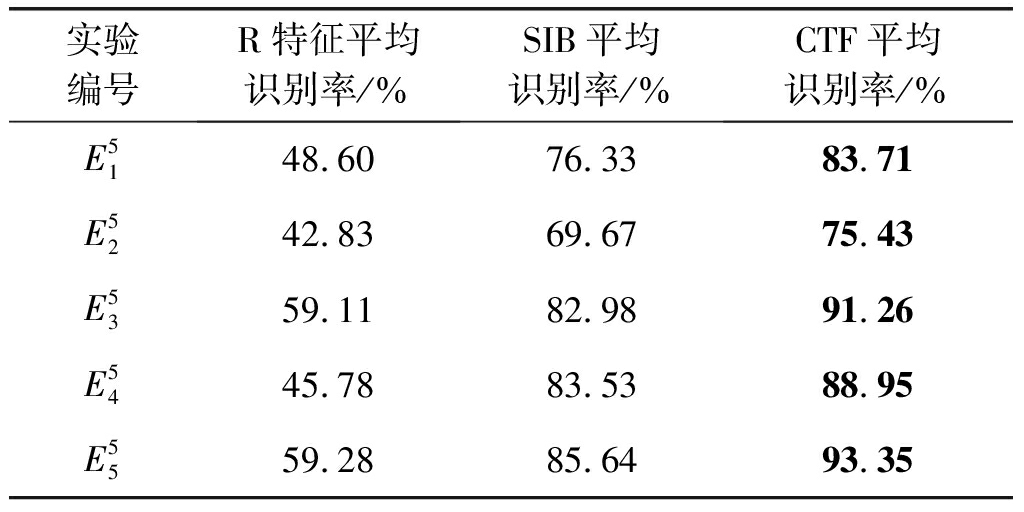
实验编号R特征平均识别率/%SIB平均识别率/%CTF平均识别率/%E5148.6076.3383.71E5242.8369.6775.43E5359.1182.9891.26E5445.7883.5388.95E5559.2885.6493.35
5 结论
本文提出了一种基于堆栈自编码器的通信辐射源指纹特征提取算法,利用大量无标签样本首先对特征提取模型进行预训练,再通过少量有标签样本进行监督精校,提高在小样本条件下对通信辐射源指纹特征的表征能力。实验结果表明,本文提出的算法显著改善了小样本条件下通信辐射源指纹特征提取能力。
参考文献
[1] 柳征. 辐射源调制分类与个体识别技术研究[D]. 长沙:国防科学技术大学,2005.
Liu Zheng. Research on Classification and Individual Recognition Technology of Radiation Source[D]. Changsha: National University of Defense Technology, 2005.(in Chinese)
[2] 唐哲,雷迎科. 通信辐射源个体识别中基于l2正则化的最大相关熵算法[J]. 通信学报, 2016,29(6):527-533.
Tang Zhe,Lei Yingke. Algorithm of Maximum Correntropy Based on l2-Regularization in Individual Communication Transmitter Identification[J]. Journal on Communication,2016,29(6):527-533.(in Chinese)
[3] 蔡忠伟,李建东. 基于双谱的通信辐射源个体识别[J]. 通信学报,2007,28(2):75-79.
Cai Zhongwei,Li Jiandong. Study of Transmitter Individual Identification Based on Bispectra[J]. Journal on Communication,2007,28(2):75-79. (in Chinese)
[4] 顾晨辉, 王伦文. 基于瞬时包络特征的跳频电台个体识别方法[J]. 信号处理, 2012, 28(9):1335-1340.
Gu Chenhui, Wang Lunwen. Individual frequency hopping radio identification method based on instantaneous envelope characteristics[J]. Signal Processing, 2012, 28(9):1335-1340. (in Chinese)
[5] 梁江海,黄知涛,袁英俊,等. 一种经验模态分解的通信辐射源个体识别方法[J]. 中国电子科学研究院学报, 2013, 8(4):393-397.
Liang Jianghai, Huang Zhitao, Yuan Yingjun, et al. A Method Based on Empirical Decomposition for Identifying Transmitter Individuals[J]. Journal of CAEIT, 2013, 8(4): 393-397. (in Chinese)
[6] 余凯,贾磊,陈雨强.深度学习的昨天、今天和明天[J].计算机研究与发展, 2013, 50(9):1799-1804.
Yu Kai,Jia Lei,Chen Yuqiang. Deep Learning’s Yesterday, Today and Tomorrow[J]. Computer Research and Development, 2013,50(9):1799-1804. (in Chinese)
[7] Hinton G. Reducing the Dimensionality of Data with Neural Network[J]. Science, 2006, 313:504-507.
[8] Ouyang Wanli,Wang Xiaogang. Joint Deep Learning for Pedestrian Detection[C]∥The IEEE International Conference Vision(ICCV),2013: 2056-2063.
[9] 马勇,鲍长春. 基于稀疏神经网络的说话人分割[J]. 北京工业大学学报, 2015, 41(5): 662- 667.
Ma Yong, Bao Changchun. Speaker Segmentation Based on Sparse Neural Network[J]. Journal of Beijing University of Technology, 2015, 41(5):662- 667. (in Chinese)
[10] Kenny P,Boulianne G,Ouellet P,et al. Joint Factor Analysis Versus Eigenchannels in Speaker Recognition[J]. IEEE Transaction on Audio,Speech,and Language Processing,2007,15(4):1435-1447.
[11] 彭君睿.面向文本分类的特征提取算法研究[D].北京:北京邮电大学,2013.
Peng Junrui. A Research on Feature Extraction Applied for Text Classification [D]. Beijing: Beijing University of Posts and Telecommunications, 2013. (in Chinese)
[12] Deep Learning Tutorial[EB/OL]. 2013. http:∥deeplearning. Net / tutorial /.
[13] 周东青,王玉冰,王星,等. 基于深度限制玻尔兹曼机的辐射源信号识别[J]. 国防科技大学学报, 2016, 38(6):136-141.
Zhou Dongqing, Wang Yubing, Wang Xing, et al. Radar Emitter Signal Recognition Based on Deep Restricted Boltzmann Machine[J]. Journal of National University of Defense Technology, 2016,38(6): 136-141.(in Chinese)
[14] 雷迎科,郝晓军,韩慧,等. 一种新颖的通信辐射源个体细微特征提取方法[J]. 电波科学学报, 2016,31(1):98-105.
Lei Yingke,Hao Xiaojun,Han Hui,et al. A Novel Fine Feature Extraction Method for Identifying Communication Transmitter[J]. Chinese Journal of Radio Science, 2016,31(1): 98-105. (in Chinese)
[15] 徐书华,黄本雄,徐丽娜. 基于SIB/PCA的通信辐射源个体识别[J]. 华中科技大学学报: 自然科学版,2008,36(7):14-17.
Xu Shuhua, Huang Benxiong, Xu Lina. Identification of Individual Radio Transmitters using SIB/PCA[J]. Journal of Huazhong University of Science and Technology: Natural Science Edition, 2008, 36(7):14-17.(in Chinese)

