
Exact Feature Distribution Matching and Multi-domain Information Fusion for Person Re-identification
-
摘要: 无监督域自适应行人重识别(Unsupervised Domain Adaptation for person Re-identification, UDA-ReID)任务致力于将知识从已标记的源域数据转移到目标域。和传统的单源域自适应相比,将多源域的知识迁移到目标域是一项更具挑战性的任务。由于领域上的差距,多数据集的简单组合只能产生有限的改进。针对此问题,提出了一种基于精确特征分布匹配和多域信息融合的多源域对比学习(exact feature distribution Matching and multi-domain information Fusion based Multi-domain Contrastive Learning, MFMCL)方法。该方法首先采用具有混合记忆的自步对比学习提取不同域数据的特征,并对提取到的特征进行构图,然后通过两层残差图卷积网络进行多域特征融合。其次,为了增强交叉分布特征、产生更丰富的信息,通过基于排序算法的精确直方图匹配来实现精确特征分布匹配,以获得更多样化的特征增强。实验表明,与目前先进的无监督域自适应行人重识别方法相比,所提出的MFMCL方法在广泛使用的行人重识别数据集Market1501、MSMT17和Duke上都取得了优越的性能。Abstract: The task of unsupervised domain adaptation for person re-identification (UDA-ReID) is to transfer knowledge from the marked source domain to the unmarked target domain. Compared with the traditional single-source domain adaptation, it is a more challenging task to transfer multi-source domain knowledge to the target domain. Due to the gap between different domains, the simple combination of multiple datasets can only be improved limited. To solve this problem, a multi-domain contrastive learning method based on exact feature distribution matching and multi-domain information fusion (MFMCL) was proposed. This method firstly extracted the features of data in different domains based on the self-paced contrastive learning with hybrid memory, and constructed the knowledge graph based on the extracted features, and then fused the multi-domain features through the two-layer residual graph convolution network. In addition, in order to enhance the cross distribution features between different domains and generate more abundant image style information, the exact feature distribution matching was realized by accurate histogram matching based on sorting algorithm, so as to obtain more diversified feature enhancement. Compared with the advanced UDA-ReID methods, the experimental results show that our proposed MFMCL method achieves the best performance on the widely used ReID datasets Market1501, MSMT17 and Duke.
-
1. 引言
随着大规模数据集的出现,以及特征提取和度量学习方法的改进,行人重识别(person Re-identification, ReID)受到了很多关注[1]。无监督域自适应行人重识别(Unsupervised Domain Adaptation for person Re-identification, UDA-ReID)[2]旨在将源域上训练的模型自适应到未身份注释的目标域。UDA-ReID任务提出了许多新的方法[3-9],这些方法主要分为三类:域特征对齐、图像风格迁移和基于集群聚类的方法。其中,基于集群聚类生成伪标签的自步对比学习(Self-paced Contrastive Learning, SpCL)[8]方法表现出卓越的性能。
虽然SpCL采用对比学习训练网络并通过混合记忆存储器在线微调伪标签,在正确识别无标注数据上取得了先进的效果,但是该模型仅使用单一源域的有限数据进行训练,在实际应用中对目标域的积极影响往往是有限的,且其他标记的数据集没有得到充分的利用。为了充分利用包含许多变化和环境因素的训练数据并且进一步提高网络对未标记数据的识别性能,本文着重于研究如何将仅单一源域训练的对比学习模型应用到多源域UDA-ReID任务[10-11]上,并提出多源域对比学习模型。然而,由于多个源域与目标域之间具有领域差异,仅仅将多个数据集简单组合作为训练数据可能会导致模型过拟合,甚至阻碍该模型的泛化能力。
随着图卷积网络(Graph Convolutional Network, GCN)[12]的广泛应用,在多标签图像分类模型[13]中,XU等人提出在目标域和不同源域的原型上构造一个知识图,然后利用图卷积网络GCN模型对知识图中的每个节点进行信息传递并输出分类概率。该方法通过各个域的原型之间的信息传递来实现域的融合,可以有效缓解不同域之间的领域差异,从而灵活地辅助目标域预测。另外,Bai等人[14]利用GCN提出了一种无监督多源域自适应(Unsupervised Multi-Source Domain Adaptation, UMSDA)方法,并通过实验表明了基于GCN的多域信息融合(Multi-Domain Information Fusion, MDIF)对减小不同行人数据之间领域差异的有效性。受上述启发,为了解决多源域UDA-ReID任务中存在的问题,本文在多源域对比学习模型中引入多域信息融合方法,在不同域的域代理节点之间以及不同域中所有实例节点之间分别构建一个知识图,并分别将其在两层GCN网络中传播,从而实现不同域行人特征之间的信息融合。相比于UMSDA中所使用的同步平均教学(Mutual Mean-Teaching, MMT)[7]框架,本文所采用的基于混合记忆存储器的对比学习框架能够为网络生成更为可靠的行人伪标签,且不会额外增加网络模型参数。因此,本文将多源域对比学习与GCN相结合,能够使网络取得更好的识别性能。
此外,研究者指出可以将域适应转化为一个特征分布匹配问题,通过交叉分布的特征匹配来进一步提升域泛化能力[15-16]。在高斯特征分布的假设下,传统的特征分布匹配方法通常与特征的均值和标准差相匹配。然而,真实数据的特征分布通常比高斯分布复杂得多,高斯分布除了均值和标准差外,还有高阶统计量,使用高阶特征统计量可以更准确地表示样式信息,实现特征增强。为了在不增加计算量的情况下充分利用高阶统计量,Zhang等人首次提出了精确特征分布匹配(Exact Feature Distribution Matching, EFDM)[17],并通过精确匹配图像高阶特征的经验累积分布函数来实现特征增强。基于Zhang等人[17]的研究启发,本文的多源域对比学习模型还同时考虑了在特征提取时通过应用EFDM方法生成语义信息保留和风格转移的特征增强,从而进一步改善跨域性能。
综上所述,针对多源域UDA-ReID任务中存在的源域和目标域之间的特征分布差异以及多源数据集训练时存在的域差异问题,本文对SpCL框架进行了改进,提出了一种基于精确特征分布匹配和多域信息融合的多源域对比学习(exact feature distribution Matching and multi-domain information Fusion based Multi-domain Contrastive Learning, MFMCL)框架,以进一步提升跨域行人重识别的识别性能。创新点如下:
(1)提出了一种基于精确特征分布匹配和多域信息融合的多源域对比学习框架。该框架通过嵌入精确特征分布匹配模块增强不同域之间的交叉特征,接着利用多域信息融合模块融合多个源域的特征,减少域距离,同时,使用三个混合特征存储器存储不同域的聚类信息,最后通过多源域对比损失训练网络。
(2)针对源域和目标域之间的特征分布差异问题,所提出的多源域对比学习框架在特征提取的低层引入精确特征分布匹配模块,利用高阶统计数据高效隐式地进行特征分布匹配,实现了在保留源域语义信息的同时增强源域和目标域之间的交叉分布特征。
(3)针对多源数据集训练时存在的域差异问题,所提出的多源域对比学习框架在池化层后嵌入了多域信息融合模块,该模块使域信息能够在域代理节点和编码特征之间传播,从而实现域融合,减少域距离。
2. 相关工作
2.1. 无监督域自适应行人重识别
UDA-ReID的目的是将在有标记的源域数据集上训练的模型调整到目标域数据集,而无须进行任何进一步的注释。其中,基于聚类的方法表现出卓越的性能,例如同步平均教学(Mutual Mean-Teaching, MMT)[7]和自步对比学习(SpCL)[8]框架。该聚类方法使用标记源域数据的特征预训练、对目标域数据的基于聚类的伪标签预测,并使用伪标签的特征表示学习和微调。MMT利用更为鲁棒的软标签对伪标签进行在线优化,从而有效解决聚类算法中的伪标签噪声问题。SpCL将所有源域类标签、目标域聚类伪标签、非聚类实例存储到混合记忆存储器,并设计了一个统一的框架来动态更新和判别混合记忆存储器里不同的入口,能够跨域为联合学习判别特征表示提供有监督信号。由于聚类算法的不完善以及源数据与目标数据的域差距,使分配的伪标签包含不正确的标签,导致误导特征学习,影响域自适应能力。群感知标签转移(Group-aware Label Transfer, GLT)算法[9]被提出来解决这类问题,该算法将在线标签细化和群感知策略相结合,从而更好地在线纠正噪声伪标签,使预测更准确。另一方面,基于内存的多源元学习(Memory-based Multi-Source Meta Learning, M3L)框架[10]引入元学习策略来模拟领域泛化的训练测试过程,同时克服了不稳定的元优化。然而,M3L等方法使用一个专家模型为不同的源域学习一个共同的特征空间,这可能会忽略单个域的区别信息。XU等人通过研究多个专家模型的混合模型,提出了基于自适应聚合的模拟嵌入(Mimic Embedding via adapTive Aggregation, META)[11]方法,并利用域特定归一化层和全局分支来分别解决模型的可伸缩性和领域不变性,以改善多源域泛化问题。
2.2. 特征分布匹配
直方图匹配(Histogram Matching, HM)[15]是一种经典的特征匹配方法,该方法除了匹配一阶和二阶特征统计量外,还引入高阶统计量来进行匹配,但同时也极大的增加了计算开销。HM在图像像素空间的输出差虽然很小,但这种微小的差异会在深度模型的特征空间中被放大,导致特征分布匹配存在明显的差异。精确直方图匹配(Exact histogram matching, EHM)[18]提出通过排序匹配来精确匹配图像像素的直方图。该方法随机或局部平均地区分等效像素值,并应用元素级变换,获得更准确的直方图匹配。其中的排序匹配是基于快速排序的策略[19],被认为是速度最快的排序算法。根据自适应实例规范化(Adaptive Instance Normalization, AdaIN)特征分布匹配技术[20],混合风格(Mix Stytle, MixStytle)[16]方法提出随机选择多个不同域的实例,并在底部CNN层的实例级特征之间采用概率凸组合的方式匹配高斯统计量,增强了交叉分布特征。然而,真实数据集的特征分布往往比高斯分布复杂得多,此时AdaIN匹配的特征分布精度降低。
2.3. 图卷积网络
知识图谱描述了实体及其相互关系,并组织在一个图中。在多标签图像分类任务中,WANG等人[13]提出利用知识图谱来显示其语义关系。图卷积网络(Graph Convolutional Network, GCN)[12]被设计用于直接计算图结构的数据,建模内部结构关系,从而在知识图谱上传播信息。目前图卷积网络已经被广泛应用于各种计算机视觉任务中,例如监督行人重识别[21-22]、动作识别[23]等。在多源域自适应领域,最近研究表明图卷积网络在减少领域差异方面表现出了显著的效果[13]。无监督多源域自适应(Unsupervised Multi-Source Domain Adaptation, UMSDA)方法[14]提出通过图卷积网络来减少行人数据间的领域距离。学会组合的多源领域自适应(Learning to Combine for Multi-Source Domain Adaptation, LtC-MSDA)框架[24]提出在不同域的原型上构造一个知识图谱,以实现信息在语义相邻表示之间的传播。在此基础上学习一个图模型,在相关原型的指导下预测查询样本,以协助模型对目标域进行预测。
3. 本文方法
3.1. 整体架构
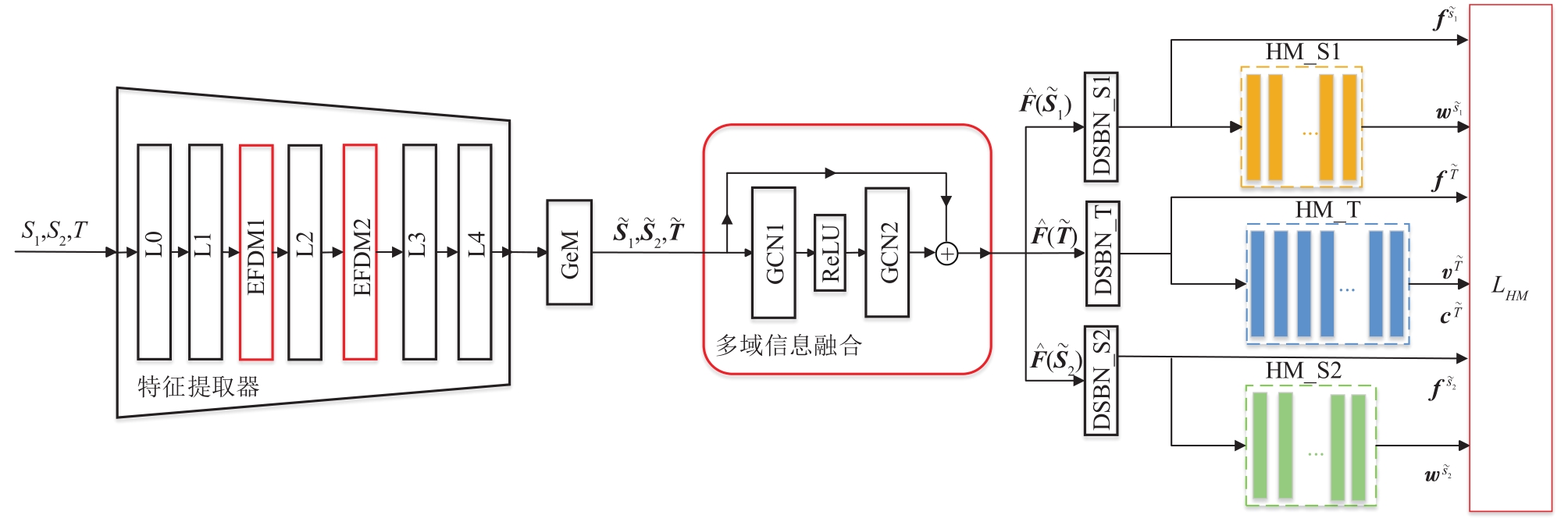
本文基于自步对比学习模型,构建了一个基于精确特征分布匹配和多域信息融合的多源域对比学习框架,该框架通过聚类生成不同级别的伪标签来训练网络,同时引入EFDM以增强行人特征,并引入GCN以实现多域信息融合,最后利用混合记忆存储器实现多源域的自步对比学习。其整体架构如图1所示。
从图1可以看出,源域样本集
S1 、S2 和目标域样本集T 分别经过特征提取器和广义均值池化(generalized-mean pooling, GeM)层后得到特征矩阵˜S1∈RN×C 、˜S2∈RN×C 和˜T∈RN×C 。网络框架中的特征提取器为截取的Resnet50[25]网络结构池化前的五个阶段,分别记为L0、L1、L2、L3和L4,且除L0外其他四部分都包含了残差块,同时分别在L1和L2层后嵌入精确特征分布匹配模块EFDM(即EFDM1和EFDM2),其中EFDM模块用于产生更多样化的行人特征信息;此外,为了进一步减少领域差异,该网络框架在GeM层后嵌入了多域信息融合模块,该模块由带有残差连接的两个图卷积网络GCN1和GCN2以及激活函数(Rectified Linear Unit, ReLU)构成,其中GCN1和GCN2的具体结构遵循图卷积网络[12]模型并且引入域代理结点。信号经多域信息融合模块处理后得到的输出矩阵分别为ˆF(˜S1) 、ˆF(˜S2) 和ˆF(˜T) ,并输入到域特定归一化层DSBN_S1、DSBN_S2和DSBN_T得到源域和目标域样本的特征编码向量f˜s1 、f˜s2 和f˜T 。一方面,得到的f˜s1 、f˜s2 和f˜T 分别进入混合记忆存储器HM_S1、HM_S2和HM_T中,分别训练得到对应的源域身份标签w˜s1 、w˜s2 和所有未聚类目标域实例特征v˜T 和目标域聚类伪标签c˜T ,同时,将上述所得结果与f˜s1 、f˜s2 和f˜T 一起进入多源域对比损失LHM 以实现迭代优化。之后利用每一轮迭代中获得的特征编码向量f˜s1 、f˜s2 和f˜T 在线微调聚类结果。3.2. 精确特征分布匹配
尽管ReID网络在源域提取和鉴别特征上表现良好,但往往不能很好地应用到目标域中,从而在跨域识别时仍表现出较低的识别精度。为了解决这个问题,本文在特征提取器模块中引入2个EFDM模块,分别嵌入到特征提取器的L1和L2层之后。嵌入的两个EFDM(EFDM1, EFDM2)模块通过在行人特征空间中应用精确直方图匹配方法,实现对高阶统计量进行高效、隐式地匹配。以EFDM1为例,其具体处理流程如下所示:
首先,对于输入的源域数据集
S ,目标域数据集T 的每一个实例,特征提取器由L1层输出到EFDM1的源域特征向量为s (包含s1 ,s2 ),目标域行人特征向量为t 。EFDM1模块首先将s 和t 按升序排序,排序后的向量分别记为s'={s'τj,j∈[1,n]} 和t'={t'ηj,j∈ [1,n]} ,其索引分别存储在向量τ 和η 中,具体表示如下:其中
s'τ1 对应s 中元素的最小值,s'τn 对应s 中元素的最大值,τ1,τn 为最小值s'τ1 与最大值s'τn 在向量s 的索引值,t'η1 对应t 中元素的最小值,t'ηn 对应t 中元素的最大值,η1,ηn 为最小值t'η1 与最大值t'ηn 在向量t 的索引值。其次,为了在深度模型中实现梯度反向传播,将排序后的两个向量s' 和t' 经过公式(2)得到匹配的输出向量为oτj 。其中,
〈⋅〉 表示停止梯度操作。另外,为了生成增强更多混合信息风格的不同特征,本文使用更加准确的方法对两个向量s' 和t' 进行处理,从而得到更精确的特征分布混合,其公式如下所示:其中
λ~Beta(α,α) ,α∈(0,∞) 为超参数。通过式(3)可以得到两个源域特征并与目标域特征输入到特征提取器的L2层。同理,EFDM2的处理流程与EFDM1类似。3.3. 多域信息融合
本文为了达到降低域差异的目的,还引入了多域信息融合模块。该模块包括带有残差连接的两层GCN,其中第一层GCN(GCN1)负责融合全局域表示,第二层GCN(GCN2)确保所有实例都能够接收来自其他域的信息。其具体流程如下所示:
第一,将源域数据集
S ,目标域数据集T 经过特征提取器和广义均值池化处理后,并输入到多域信息融合层的特征矩阵表示分别记为˜S1 、˜S2 和˜T 。第二,为了避免直接融合实例的特征容易产生与身份相关的噪声问题,本文针对不同的域数据集引入了可以表征全局域信息的域代理节点。域代理节点为对同一域的实例特征的加权组合,即
˜S1 、˜S2 和˜T 对应的域代理节点表示如下式所示:其中
ˉs1,ˉs2 表示˜S1 、˜S2 的域代理节点,ˉt 表示目标域˜T 的代理节点,N 表示˜S1 、˜S2 和˜T 的样本数量,w1n 、w2n 和wn 是可学习的权值,˜S1n ,˜S2n 和˜Tn 分别为˜S1 、˜S2 和˜T 的第n 个实例对应的向量。第三,将
˜S1 、˜S2 、˜T 和三个对应的域代理节点按行堆叠生成一个待输入到多域信息融合模块的图信号F(0)∈R(3N+3)×C ,C 为每个实例的特征维数。第四,获取第
l 个GCN层的邻接矩阵A(l) (l=1,2 )。A(l)∈R(3N+3)×(3N+3) 是根据两个实例节点之间的连接关系得到的,其A(l) 的每个元素A(l)r,c 由式(5)可得:其中,
r 和c 分别表示邻接矩阵A(l) 的行索引和列索引。其中,为了融合全局域的表示,本文使邻接矩阵A(1) 和A(2) 的三个域代理节点ˉs1 、ˉs2 和ˉt 之间存在连接,同时,为了确保所有实例都能够接收来自其他域的信息,本文使A(2) 中的˜S1 、˜S2 和˜T 对应的每个实例特征都连接到其对应的域代理节点中。另外,为了增强GCN1和GCN2对特征的表示能力,本文还对邻接矩阵A(l) 进行归一化操作,如式(6)所示:其中
Dl 为邻接矩阵A(l) 的度矩阵。最后,将上述得到的图信号
F(0) 和邻接矩阵A(l) 输入到包括带有残差连接的两层GCN的多域信息融合模块中进行处理。其中每个GCN层都可以写成一个如式(7)所示的非线性变换:其中,
ρ 为经典的非线性函数,本文采用的是带泄露的修正线性单元(Leaky Rectified Linear Unit, LeakyReLU),W 为可学习的加权矩阵。最后,将经过两层GCN处理后的结果F(2) 和原始图信号F(0) 进行残差连接处理得到最终的多域信息融合特征ˆF 为:并对其按域分解最终得到
˜S1 、˜S2 和˜T 对应的处理结果ˆF(˜S1) 、ˆF(˜S2) 和ˆF(˜T) 。通过上述多域信息融合方法,从而实现在多个域之间进行信息融合,进一步减小域间隙,提高域泛化能力。
3.4. 对比学习损失
本文使用对比学习损失
LHM 作为多源域自适应网络的整体优化损失函数。对比学习损失LHM 的输入分别为经过域特定归一化层DSBN_S1、DSBN_S2和DSBN_T得到的源域和目标域样本的特征编码向量f˜s1 、f˜s2 和f˜T ,以及通过混合记忆存储器HM_S1、HM_S2和HM_T分别对上述三个特征向量进行训练后的源域身份标签w˜s1 、w˜s2 以及所有未聚类目标域实例特征v˜T 和目标域聚类伪标签c˜T 。其过程如下所述:第一,在混合记忆存储器HM_S1和HM_S2里分别初始化源域身份标签
w˜s1∈RN×ns1 ,w˜s2∈RN×ns2 ,并将其堆叠为w˜s=w˜s1⋃w˜s2 ,同时,在HM_T中初始化所有未聚类目标域实例特征v˜T∈RN×nv 和目标域聚类伪标签c˜T∈RN×nc 。其中ns1,ns2 为源域类别的数量,nc 为目标域集群聚类的数量,nv 为目标域非集群实例特征的数量。第二,在训练过程中不断更新聚类结果,并通过公式(9)~(11)将属于
k 类的源域身份标签w˜sk 以及所有未聚类目标域实例特征v˜T 和目标域聚类伪标签c˜T 进行更新,更新过程如下式所示:其中,
f˜s=f˜s1⋃f˜s2 ,f˜si 是f˜s 第i 个特征向量,f=f˜s1⋃f˜s2⋃f˜T ,f˜Ti 是f˜T 的第i 个特征向量,v˜Ti 是v˜T 的第i 个特征向量,c˜Tk 是属于第k 类的目标域聚类伪标签,ms∈[0,1] 表示更新源域类质心的动量系数,mt∈[0,1] 表示更新目标域实例的动量系数;Dk 表示属于源域类k 的特征集;Ik 表示包含聚类k 中所有特征向量的第k 个聚类集,|⋅| 表示该集合中的特征数。第三,本文采用对比损失
LHM 进行训练,使编码的特征向量不断接近其分配的类别,其公式如下所示:其中
q(fi,w˜sk)=ns∑k=1exp(〈fi,w˜sk〉/σ) ,q(fi,c˜Tk)=ntc∑k=1 exp(〈fi,c˜Tk〉/σ) ,q(fi,v˜Ti)=ntv∑k=1exp(〈fi,v˜Ti〉/σ) 。〈⋅,⋅〉 表示两个特征向量之间的内积,z+ 表示与fi 对应的正类原型,σ 为温度参数。4. 实验结果与分析
4.1. 数据集与评价指标
目前广泛使用的ReID数据集有Market1501[26]、MSMT17[27]和Duke[28],此外还有小规模数据集CUHK03(新协议)[29]。本文在这几个数据集上验证了提出的基于精确特征分布匹配和多域信息融合的多源域对比学习网络的有效性和优越性。
本文实验主要使用两个定量评估指标:rank-n和平均均值精度(mean Average Precision, mAP)。rank-n指的是在搜索的前
n 个结果中正确结果的分数,表1和表2中分别简记为R-1、R-5和R-10。在算法返回的排序列表中,通过计算前n 个图像中的正确分类的图像的数量来获得排名的准确性。图像分类任务中大多数都有多种标签,mAP则是多分类任务中平均精度的平均总和,是ReID任务中常用的定量评估指标。表 1 识别结果(%)Tab. 1. Recognition results(%)方法 MSMT17+CUHK03->Market1501 Market1501+CUHK03->MSMT17 Market1501+CUHK03->Duke mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 M-SpCL 89.3 93.0 96.2 97.0 37.0 63.1 70.7 74.3 80.4 85.0 91.6 93.6 M-SpCL+EFDM 89.5 93.6 96.3 97.3 37.6 63.9 72.2 74.7 80.6 85.9 91.7 93.7 M-SpCL+MDIF 89.4 93.3 96.3 97.0 38.5 63.5 71.3 74.8 80.8 85.9 91.7 93.6 MFMCL 90.0 93.8 96.7 97.5 38.9 64.9 73.0 76.3 81.4 86.9 92.2 93.7 表 2 不同UDA-ReID方法的识别结果(%)Tab. 2. Recognition results of different UDA-ReID methods(%)方法单源域 MSMT17->Market1501 Market1501->MSMT17 Market1501->Duke mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 MMT 86.7 90.7 95.0 96.7 34.5 57.2 66.3 70.6 77.6 81.4 87.8 91.1 SpCL 87.2 91.4 95.5 96.8 34.6 60.6 68.9 72.7 79.1 84.6 90.4 92.6 GLT 87.6 92.2 96.0 96.9 34.3 61.8 69.3 73.1 79.0 83.8 90.4 92.7 多源域 MSMT17+CUHK03->Market1501 Market1501+CUHK03->MSMT17 Market1501+CUHK03->Duke M3L 66.8 78.5 85.9 88.6 13.8 27.7 37.1 41.9 43.3 53.9 64.7 68.9 META 67.3 80.4 87.8 91.4 25.2 48.1 57.7 62.6 59.3 69.2 78.5 82.7 UMSDA 89.6 92.2 95.6 96.6 23.6 43.5 52.2 56.8 76.7 81.9 87.8 90.6 MFMCL 90.0 93.8 96.7 97.5 38.9 64.9 73.0 76.3 81.4 86.9 92.2 93.6 4.2. 实验细节
本文使用Resnet50作为特征提取的骨干网络,动量优化选择Adam优化算法,其权值衰减率为0.0005。模型初始学习率设置为0.00035,并在每迭代20轮之后缩小10%。实验中设置EFDM中的超参数
α=0.1 ,并采用0.5的概率来决定EFDM在训练阶段是否被激活。公式(12)中的温度参数σ 参考文献[8]设置为0.05。源域身份标签w˜s1 ,w˜s2 初始化为数据集给定的原始身份标签,v˜T 和c˜T 都初始化为0 。伪标签生成遵循基于聚类的方法,使用具有噪声的基于密度的空间聚类方法[8]进行近距离聚类。混合记忆存储器通过使用图像预训练编码器提取整个训练集进行初始化,然后动态更新公式(9)和(10),其中ms=mt=0.2 。4.3. 消融实验
本小节分别以Market1501、MSMT17和Duke作为消融实验中无标注的测试数据集,以验证在本文所提出的基于精确特征分布匹配和多域信息融合的多源域对比学习模型对多源域自适应行人重识别识别性能的影响。将经过调整和配置后得到的网络模型作为实验的强基线模型,记为M-SpCL。在特征提取网络底层嵌入EFDM进行图像特征增强,然后在特征提取后采用残差GCN进行多域信息融合,并分别验证其有效性,实验结果如表1所示。
表1中,“MSMT17+CUHK03->Market1501”是指MSMT17和CUHK03为源域,Market1501为目标域,其余类似。从表1中可以看出,引入的M-SpCL+EFDM、M-SpCL+MDIF都比基线模型M-SpCL具有更好的性能,提出的MFMCL即同时融合了两者的对比学习模型的改善效果更为显著。具体来说,提出的MFMCL与M-SpCL相比,在Market1501数据集上mAP提升了0.7%,rank-1提升了0.8%;在MSMT17数据集上mAP提升了1.9%,rank-1提升了1.8%;在Duke数据集上mAP提升了1.0%,rank-1提升了1.9%。可以得出结论,首先,EFDM在多源域对比学习模型中起着积极的作用,它使得模型在训练时保留了更多的源域匹配信息。其次,通过采用基于GCN的多域信息融合方法,使对比学习模型能够对提取到的多源域信息进行融合,以改善模型性能。最后,两种方法的组合得到提出的基于MFMCL的多源域对比学习模型,取得了最佳的性能。
4.4. 对比实验
为了验证所提出的基于精确特征分布匹配和多域信息融合的多源域对比学习模型的优越性,将其与先进的UDA-ReID方法MMT[7]、SpCL[8]、GLT[9]、M3L[10]、META[11]及UMSDA[14]进行比较。表2中给出了本文提出的方法和其他先进的UDA-ReID方法的对比结果。
由表2可以看出,与次最佳性能的域适应方法GLT相比,以Market1501为测试数据集时,提出的MFMCL分别在mAP和rank-1上提高了2.4%和1.6%;以MSMT17为测试数据集时,提出的方法分别在mAP和rank-1上提高了4.6%和3.1%;以Duke为测试数据集时,与次最佳域适应方法SpCL相比,提出的方法分别在mAP和rank-1上提高了2.3%和2.3%。此外,以MSMT17和CUHK03为源域,Market1501为目标域时,与次最佳性能的多源域模型UMSDA相比,提出MFMCL在mAP和rank-1上分别高出0.4%和1.6%;以Market1501和CUHK03为源域,MSMT17为目标域时,与次最佳的多源域模型META相比,提出的方法在mAP和rank-1上分别高出13.7%和16.8%;以Market1501和CUHK03为源域,Duke为目标域时,与次最佳的多源域模型UMSDA相比,提出的方法在mAP和rank-1上分别高出4.7%和5.0%,表明本方法对于多源域任务适应性更强。总体来说,本文基于自步对比学习策略所构建的基于精确特征分布匹配和多域信息融合的多源域对比学习架构,在定性识别精度上表现出了较强的性能,远远超越了现有的方法。
5. 结论
本文针对多源域自适应行人重识别任务,提出了一种基于精确特征分布匹配和多域信息融合的多源域对比学习框架。为了提高源域与目标域的交叉特征匹配,提出采用精确特征分布匹配方法,隐式地利用高阶统计数据进行交叉分布特征匹配,以实现更多样化的特征增强。并通过基于图卷积网络的多域信息融合方法进一步减小域距离。另外,将采用聚类算法获得的目标域数据的伪标签存入混合记忆存储器中,并计算多源域对比学习损失以优化模型。最后,在开放ReID数据集Market1501、MSMT17和Duke上进行了详细的消融实验和对比实验。实验结果表明,提出的MFMCL方法显著提高了多源域自适应行人重识别的性能。
-
表 1 识别结果(%)
Table 1 Recognition results(%)
方法 MSMT17+CUHK03->Market1501 Market1501+CUHK03->MSMT17 Market1501+CUHK03->Duke mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 M-SpCL 89.3 93.0 96.2 97.0 37.0 63.1 70.7 74.3 80.4 85.0 91.6 93.6 M-SpCL+EFDM 89.5 93.6 96.3 97.3 37.6 63.9 72.2 74.7 80.6 85.9 91.7 93.7 M-SpCL+MDIF 89.4 93.3 96.3 97.0 38.5 63.5 71.3 74.8 80.8 85.9 91.7 93.6 MFMCL 90.0 93.8 96.7 97.5 38.9 64.9 73.0 76.3 81.4 86.9 92.2 93.7  下载: 导出CSV
下载: 导出CSV
表 2 不同UDA-ReID方法的识别结果(%)
Table 2 Recognition results of different UDA-ReID methods(%)
方法单源域 MSMT17->Market1501 Market1501->MSMT17 Market1501->Duke mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 mAP R-1 R-5 R-10 MMT 86.7 90.7 95.0 96.7 34.5 57.2 66.3 70.6 77.6 81.4 87.8 91.1 SpCL 87.2 91.4 95.5 96.8 34.6 60.6 68.9 72.7 79.1 84.6 90.4 92.6 GLT 87.6 92.2 96.0 96.9 34.3 61.8 69.3 73.1 79.0 83.8 90.4 92.7 多源域 MSMT17+CUHK03->Market1501 Market1501+CUHK03->MSMT17 Market1501+CUHK03->Duke M3L 66.8 78.5 85.9 88.6 13.8 27.7 37.1 41.9 43.3 53.9 64.7 68.9 META 67.3 80.4 87.8 91.4 25.2 48.1 57.7 62.6 59.3 69.2 78.5 82.7 UMSDA 89.6 92.2 95.6 96.6 23.6 43.5 52.2 56.8 76.7 81.9 87.8 90.6 MFMCL 90.0 93.8 96.7 97.5 38.9 64.9 73.0 76.3 81.4 86.9 92.2 93.6
下载: 导出CSV
-
[1] YE Mang,SHEN Jianbing,LIN Gaojie,et al. Deep learning for person re-identification:A survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44(6):2872- 2893. doi:10.1109/tpami.2021.3054775 doi: 10.1109/tpami.2021.3054775
[2] LIN X T,REN P Z,YEH C,et al. Unsupervised person re-identification:a systematic survey of challenges and solutions[EB/OL]. 2021:arXiv:2109.06057[cs.CV]. https://arxiv.org/abs/2109.06057.
[3] WANG Mei,DENG Weihong. Deep visual domain adaptation:A survey[J]. Neurocomputing,2018,312:135- 153. doi:10.1016/j.neucom.2018.05.083 doi: 10.1016/j.neucom.2018.05.083
[4] MEKHAZNI D,BHUIYAN A,EKLADIOUS G,et al. Unsupervised domain adaptation in the dissimilarity space for person re-identification[C]// Computer Vision-ECCV 2020,2020:159- 174. doi:10.1007/978-3-030-58583-9_10 doi: 10.1007/978-3-030-58583-9_10
[5] ZOU Y,YANG X D,YU Z D,et al. Joint disentangling and adaptation for cross-domain person re-identification[C]. Proceedings of the European Conference on Computer Vision(ECCV). Glasgow,UK. Springer,2020:87- 104. doi:10.1007/978-3-030-58536-5_6 doi: 10.1007/978-3-030-58536-5_6
[6] CHEN Hao,WANG Yaohui,LAGADEC B,et al. Joint generative and contrastive learning for unsupervised person re-identification[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:2004- 2013. doi:10.1109/cvpr46437.2021.00204 doi: 10.1109/cvpr46437.2021.00204
[7] GE Y,CHEN D,LI H. Mutual mean-teaching:pseudo label refinery for unsupervised domain adaptation on person re-identification[C]. Proceedings of the International Conference on Learning Representation(ICLR). Addis Ababa,Ethiopia. ICLR:2020:1- 15.
[8] GE Y,ZHU F,CHEN D,et al. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id[J]. Proceedings of the Neural Information Processing Systems,2020:11309- 11321.
[9] ZHENG Kecheng,LIU Wu,HE Lingxiao,et al. Group-aware label transfer for domain adaptive person re-identification[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:5306- 5315. doi:10.1109/cvpr46437.2021.00527 doi: 10.1109/cvpr46437.2021.00527
[10] ZHAO Yuyang,ZHONG Zhun,YANG Fengxiang,et al. Learning to generalize unseen domains via memory-based multi-source meta-learning for person re-identification[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:6273- 6282. doi:10.1109/cvpr46437.2021.00621 doi: 10.1109/cvpr46437.2021.00621
[11] XU B Q,LIANG J,HE L X,et al. Mimic embedding via adaptive aggregation:learning generalizable person re-identification[EB/OL]. 2022:arXiv:2112. 08684 v3[cs.CV]. https://arxiv.org/abs/2112.08684v3. doi:10.1007/978-3-031-19781-9_22 doi: 10.1007/978-3-031-19781-9_22
[12] KIPF T N,WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. 2017:arXiv:1609.02907[cs.LG]. https://arxiv.org/abs/1609.02907.
[13] XU Minghao,WANG Hang,NI Bingbing. Graphical modeling for multi-source domain adaptation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2022:1. doi:10.1109/tpami.2022.3172372 doi: 10.1109/tpami.2022.3172372
[14] BAI Zechen,WANG Zhigang,WANG Jian,et al. Unsupervised multi-source domain adaptation for person re-identification[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:12909- 12918. doi:10.1109/cvpr46437.2021.01272 doi: 10.1109/cvpr46437.2021.01272
[15] KALISCHEK N,WEGNER J D,SCHINDLER K. In the light of feature distributions:Moment matching for Neural Style Transfer[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:9377- 9386. doi:10.1109/cvpr46437.2021.00926 doi: 10.1109/cvpr46437.2021.00926
[16] ZHOU K Y,YANG Y X,QIAO Y,et al. Domain generalization with mixstyle[C]. International Conference on Learning Representations(ICLR). Venice,Italy. ICLR,2021:1- 15. doi:10.1109/icarm54641.2022.9959388 doi: 10.1109/icarm54641.2022.9959388
[17] ZHANG Yabin,LI Minghan,LI Ruihuang,et al. Exact feature distribution matching for arbitrary style transfer and domain generalization[C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). New Orleans,LA,USA. IEEE,2022:8025- 8035. doi:10.1109/cvpr52688.2022.00787 doi: 10.1109/cvpr52688.2022.00787
[18] COLTUC D,BOLON P,CHASSERY J M. Exact histogram specification[J]. IEEE Transactions on Image Processing,2006,15(5):1143- 1152. doi:10.1109/tip.2005.864170 doi: 10.1109/tip.2005.864170
[19] ROLLAND J P,VO V,BLOSS B,et al. Fast algorithms for histogram matching:Application to texture synthesis[J]. Journal of Electronic Imaging,2000,9:39- 45. doi:10.1117/1.482725 doi: 10.1117/1.482725
[20] HUANG Xun,BELONGIE S. Arbitrary style transfer in real-time with adaptive instance normalization[C]// 2017 IEEE International Conference on Computer Vision. Venice,Italy. IEEE,2017:1510- 1519. doi:10.1109/iccv.2017.167 doi: 10.1109/iccv.2017.167
[21] YAN Yichao,ZHANG Qiang,NI Bingbing,et al. Learning context graph for person search[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Long Beach,CA,USA. IEEE,2019:2153- 2162. doi:10.1109/cvpr.2019.00226 doi: 10.1109/cvpr.2019.00226
[22] JIANG Bo,WANG Xixi,LUO Bin. pH-GCN:Person re-identification with part-based hierarchical graph convolutional network[EB/OL]. 2019:arXiv:1907.08822[cs.CV]. https://arxiv.org/abs/1907.08822.
[23] 辛华磊,丁英强,高猛,等. 基于多分区时空图卷积网络的骨骼动作识别[J]. 信号处理,2022,38(2):241- 249. XIN Hualei,DING Yingqiang,GAO Meng,et al. Multi-partitioned spatiotemporal graph convolutional network for skeletal action recognition[J]. Journal of Signal Processing,2022,38(2):241- 249.(in Chinese)
[24] WANG H,XU M H,NI B B,et al. Learning to combine:knowledge aggregation for multi-source domain adaptation[C]. Proceedings of European Conference on Computer Vision(ECCV). Glasgow,UK. Springer,2020:1- 19. doi:10.1007/978-3-030-58598-3_43 doi: 10.1007/978-3-030-58598-3_43
[25] HE Kaiming,ZHANG Xiangyu,REN Shaoqing,et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV,USA. IEEE,2016:770- 778. doi:10.1109/cvpr.2016.90 doi: 10.1109/cvpr.2016.90
[26] ZHENG Liang,SHEN Liyue,TIAN Lu,et al. Scalable person re-identification:A benchmark[C]// 2015 IEEE International Conference on Computer Vision. Santiago,Chile. IEEE,2015:1116- 1124. doi:10.1109/iccv.2015.133 doi: 10.1109/iccv.2015.133
[27] WEI Longhui,ZHANG Shiliang,GAO Wen,et al. Person transfer GAN to bridge domain gap for person re-identification[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA. IEEE,2018:79- 88. doi:10.1109/cvpr.2018.00016 doi: 10.1109/cvpr.2018.00016
[28] ZHENG Zhedong,ZHENG Liang,YANG Yi. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]// 2017 IEEE International Conference on Computer Vision. Venice,Italy. IEEE,2017:3774- 3782. doi:10.1109/iccv.2017.405 doi: 10.1109/iccv.2017.405
[29] ZHONG Zhun,ZHENG Liang,CAO Donglin,et al. re-ranking person re-identification with k-reciprocal encoding[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA. IEEE,2017:3652- 3661. doi:10.1109/cvpr.2017.389 doi: 10.1109/cvpr.2017.389
-
期刊类型引用(1)
1. 杨真真,邵静,杨永鹏,吴心怡. 基于动态辅助对比学习的跨域行人重识别. 南京邮电大学学报(自然科学版). 2024(03): 63-71 .  百度学术
百度学术
其他类型引用(0)
计量
- 文章访问数: 119
- HTML全文浏览量: 20
- PDF下载量: 46
- 被引次数: 1
