
Spatiotemporal Enhancement of Video Captioning Integrating a State Space Model and Transformer
-
摘要:
视频字幕生成 (Video Captioning) 旨在用自然语言描述视频中的内容,在人机交互、辅助视障人士、体育视频解说等领域具有广泛的应用前景。然而视频中复杂的时空内容变化增加了视频字幕生成的难度,之前的方法通过提取时空特征、先验信息等方式提高生成字幕的质量,但在时空联合建模方面仍存在不足,可能导致视觉信息提取不充分,影响字幕生成结果。为了解决这个问题,本文提出一种新颖的时空增强的状态空间模型和Transformer(SpatioTemporal-enhanced State space model and Transformer, ST2)模型,通过引入最近流行的具有全局感受野和线性的计算复杂度的Mamba (一种状态空间模型),增强时空联合建模能力。首先,通过将Mamba与Transformer并行结合,提出空间增强的状态空间模型(State Space Model, SSM)和Transformer (Spatial enHanced State space model and Transformer module, SH-ST),克服了卷积的感受野问题并降低计算复杂度,同时增强模型提取空间信息的能力。然后为了增强时间建模,我们利用Mamba的时间扫描特性,并结合Transformer的全局建模能力,提出时间增强的SSM和Transformer (Temporal enHanced State space model and Transformer module, TH-ST)。具体地,我们对SH-ST产生的特征进行重排序,从而使Mamba以交叉扫描的方式增强重排序后特征的时间关系,最后用Transformer进一步增强时间建模能力。实验结果表明,我们ST2模型中SH-ST和TH-ST结构设计的有效性,且在广泛使用的视频字幕生成数据集MSVD和MSR-VTT上取得了具有竞争力的结果。具体的,我们的方法分别在MSVD和MSR-VTT数据集上的绝对CIDEr分数超过最先进的结果6.9%和2.6%,在MSVD上的绝对CIDEr分数超过了基线结果4.9%。
-
关键词:
- 视频字幕生成 /
- 视频理解 /
- 状态空间模型 /
- Transformer
Abstract: Video captioning aims to describe the content of videos using natural language, offering extensive applications in areas such as human-computer interaction, assistance for visually impaired individuals, and sports commentary. However, the complex spatiotemporal variations within videos make it challenging to generate accurate captions. Previous methods have attempted to enhance caption quality by extracting spatiotemporal features and leveraging prior information. Despite these efforts, they often struggle with spatiotemporal joint modeling, which can lead to inadequate visual information extraction and negatively impact the quality of generated captions. To address this challenge, we propose a novel model, ST2, which enhances spatiotemporal joint modeling capabilities by incorporating Mamba—a recently popular state-space model (SSM) known for its global receptive field and linear computational complexity. By combining Mamba with the Transformer framework, we introduce a Spatially Enhanced SSM and Transformer (SH-ST) that overcomes the receptive field limitations of convolutional approaches while reducing computational complexity, thereby improving the model’s ability to extract spatial information. To further strengthen temporal modeling, we utilize Mamba’s temporal scanning characteristics in conjunction with the global modeling capabilities of the Transformer. This results in a Temporally Enhanced SSM and Transformer (TH-ST). Specifically, the features generated by SH-ST are reordered to allow Mamba to enhance the temporal relationships of these rearrange features through cross-scanning, after which the Transformer is employed to further bolster temporal modeling capabilities. Experimental results validate the effectiveness of the SH-ST and TH-ST structural designs within our ST2 model, achieving competitive results on widely used video captioning datasets, MSVD and MSR-VTT. Notably, our method surpasses state-of-the-art results, achieving a 6.9% and 2.6% improvement in absolute CIDEr scores on the MSVD and MSR-VTT datasets, respectively, and exceeding baseline results by 4.9% in absolute CIDEr scores on MSVD.
-
Keywords:
- video captioning /
- video understanding /
- state space model /
- Transformer
-
1. 引言
视频字幕生成是多模态领域的重要研究课题之一,通过机器学习的方式用自然语言自动生成忠于视频的描述性句子。视频字幕生成在人机交互、辅助视障人士、体育赛事解说具有广泛的应用前景,尤其随着自动驾驶、大模型等快速发展,各界对视频字幕生成的需求仍在上升。为了能够生成准确的文本描述,需要模型充分理解视频,因此从复杂多变的视频中提取有效信息对于解码器生成文本描述至关重要。
传统的视频字幕生成主要是基于模板[1-3]的方法,首先从视觉分类器中提取主题、对象和动词等语义概念,然后根据给定句子模板生成字幕。受到模板的限制,基于模板的方法生成的字幕形式单一,缺乏灵活性。基于深度学习的方法多采用最大似然估计(Maximum Likelihood Estimation,MLE)作为损失,即以对应视觉特征为条件,训练视频字幕的概率最大化。有关算法最早可追溯到2015年利用长短时记忆网络(Long Short-Term Memory, LSTM)[4]实现的序列到序列视频字幕[5],随后基于编码器解码器结构的方法成为主流[6-10],并利用Transformer[11]取得长足的发展[12-15]。最近通过对比语言-图像预训练(Contrastive Language-Image Pre-Training, CLIP)[16]模型展现了强大的特征提取和零样本能力,利用CLIP提取视频帧的特征生成视频字幕[17-19]的方式取得令人印象深刻的性能。
近期对编码器解码器框架的改进有挖掘额外信息,如概念先验[18-20],检索信息[21-23],主题[24],目标检测[25-27]等。文献[28]通过计算文本和视频的相似性,从语料库中检索出相关的文本描述,送入解码器生成文本描述,提高了生成的多样性。然而,尽管检索出的文本描述具有较高的相似性,但不可避免地引入了较多的噪声,误导字幕的生成。文献[18]利用视觉信息提取出视频内容相关的概念,间接指导模型生成视频相关的文本描述,此种粗糙的概念提取方式会引入无关的概念噪声,直接影响生成字幕的准确性。文献[19]为提高提取的概念准确性,通过融合来自检索、音频、视频的多模态信息提取高度相关的概念,生成高效的先验信息。实验结果表明多模态信息对于概念提取以及字幕生成具有良好的效果,然而,仍无法完全避免噪声问题。上述方法中提取的先验信息,如检索、概念、主题等难以避免地产生噪声,误导模型的训练和推理,产生部分偏差的视频字幕。另外一种提升模型性能的方式是提取时间相关信息,如运动信息[25-29],运动矢量[30]等。运动信息的提取通常采用预训练模型,如3D ResNext[31],随后与视觉空间特征结合后,送入解码器解码出文本描述。文献[25]利用目标检测器检测出视频中的目标,再利用时空图模型建模目标在时空内的相互作用,并使用蒸馏将目标分支中的目标级别信息蒸馏到场景分支中,避免模型由于视频中目标的变化引起的不稳定。文献[30]提出了一种快速的端到端视频字幕生成方法,通过提取运动矢量和残差图,直接生成视频字幕。然而文献[30]提取运动矢量增加了额外的处理开销,且分别在时间和空间建模,不利于特征的时空关系的一致性,可能会对字幕生成产生消极影响。因此,避免噪声引入和时空联合建模可能会对视频字幕模型性能提升有帮助。为避免噪声引入,文献[17]利用预训练的CLIP提取丰富的特征,无须额外先验信息,特征经过Transformer编码器和解码器后直接生成文本描述。虽然文献[17]避免了提取先验信息引入噪声的问题,然而CLIP是在图像文本对上训练的,对于视频中的时间运动信息可能无法有效捕捉,仅依靠单一常规的Transformer编码器的能力难以有效建模时空信息。上述方法同样适用于其他视频理解任务[32-33],视频中时空信息提取不充分,直接影响模型的视频理解能力,限制视频字幕的生成质量。
综上所述,设计一种高效的时空建模模型成为解决问题的关键。为此,我们提出一种新颖的基于时空增强的状态空间模型(State Space Model, SSM)和Transformer模型(SpatioTemporal-enhanced State space model and Transformer, ST2),该模型引入了最近流行的Mamba模型(一种状态空间模型),SSM模型不仅克服了卷积神经网络的局部感受野问题,同时具备线性复杂度,擅长对长序列建模,具有优良的性能。为增强视频的空间特征,我们提出了空间增强的SSM和Transformer模块(Spatial enHanced State space model and Transformer module, SH-ST),利用异构的Mamba和Transformer分别处理特征。为增强时间建模能力,我们对空间特征进行重排序,提出时间增强的SSM和Transformer模块(Temporal enHanced State space model and Transformer module, TH-ST),利用SSM模型的时间扫描特性,增强时间特征建模,并再次使用Transformer提高模型表征能力。我们共享了SH-ST和TH-ST中权重,降低模型参数量的同时促进模型对视觉特征的时空联合建模。
本文的主要贡献为:①提出一种用于视频字幕生成的基于时空增强的状态空间模型和Transformer模型(ST2),有效提高视频字幕生成质量。②提出空间增强的SSM和Transformer模块(SH-ST)以及时间增强的SSM和Transformer模块(TH-ST),分别增强时间和空间信息的提取,并提高模型的时空联合建模能力。③在MSVD和MSR-VTT数据集上进行实验,定量和定性结果显示,本模型生成的视频字幕质量超越了大多数对比方法。具体的,在MSVD和MSR-VTT数据集上的绝对CIDEr分数超过最先进的结果6.9%和2.6%。
2. 网络结构
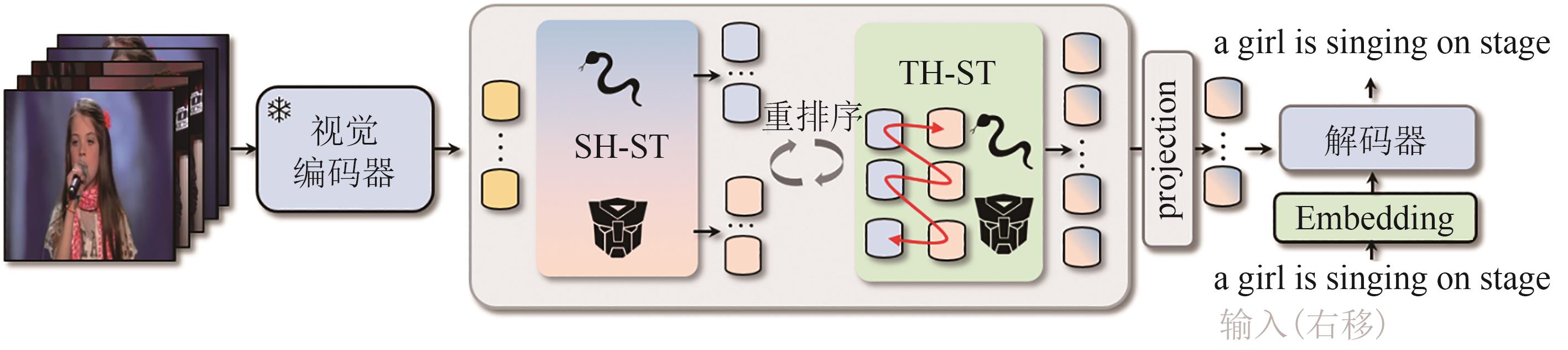
本节中我们将首先介绍SSM原理,随后详细介绍本文提出的ST2的网络架构,如图1所示,以及其两个重要组成部分空间增强的SSM和Transformer模块(SH-ST)以及时间增强的SSM和Transformer模块(TH-ST),分别如图2、图3所示,最后介绍我们采用的解码器和损失函数。
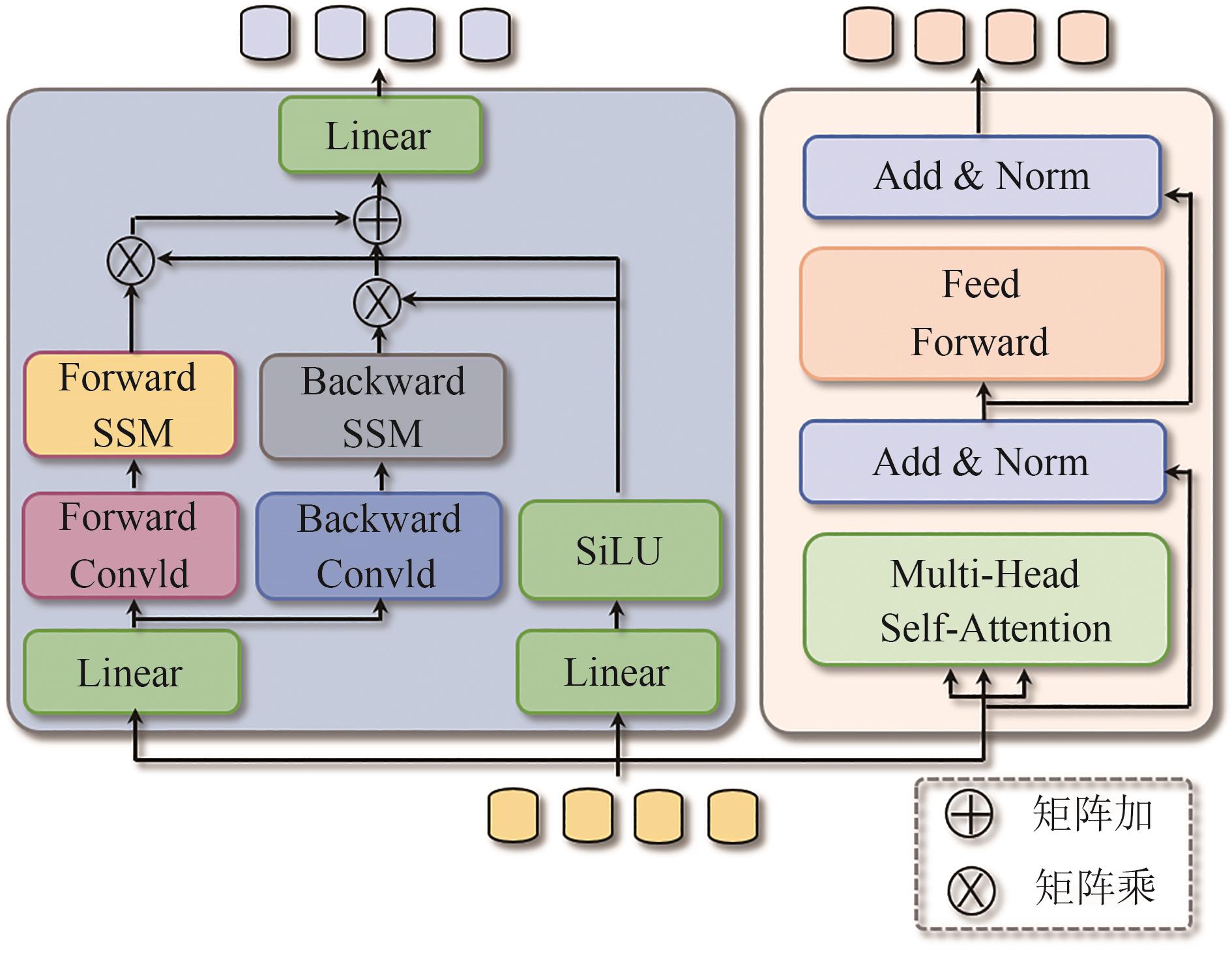
![]() 图 2 空间增强的SSM和Transformer模块Fig. 2. Spatially enhanced state space model and Transformer module (SH-ST)
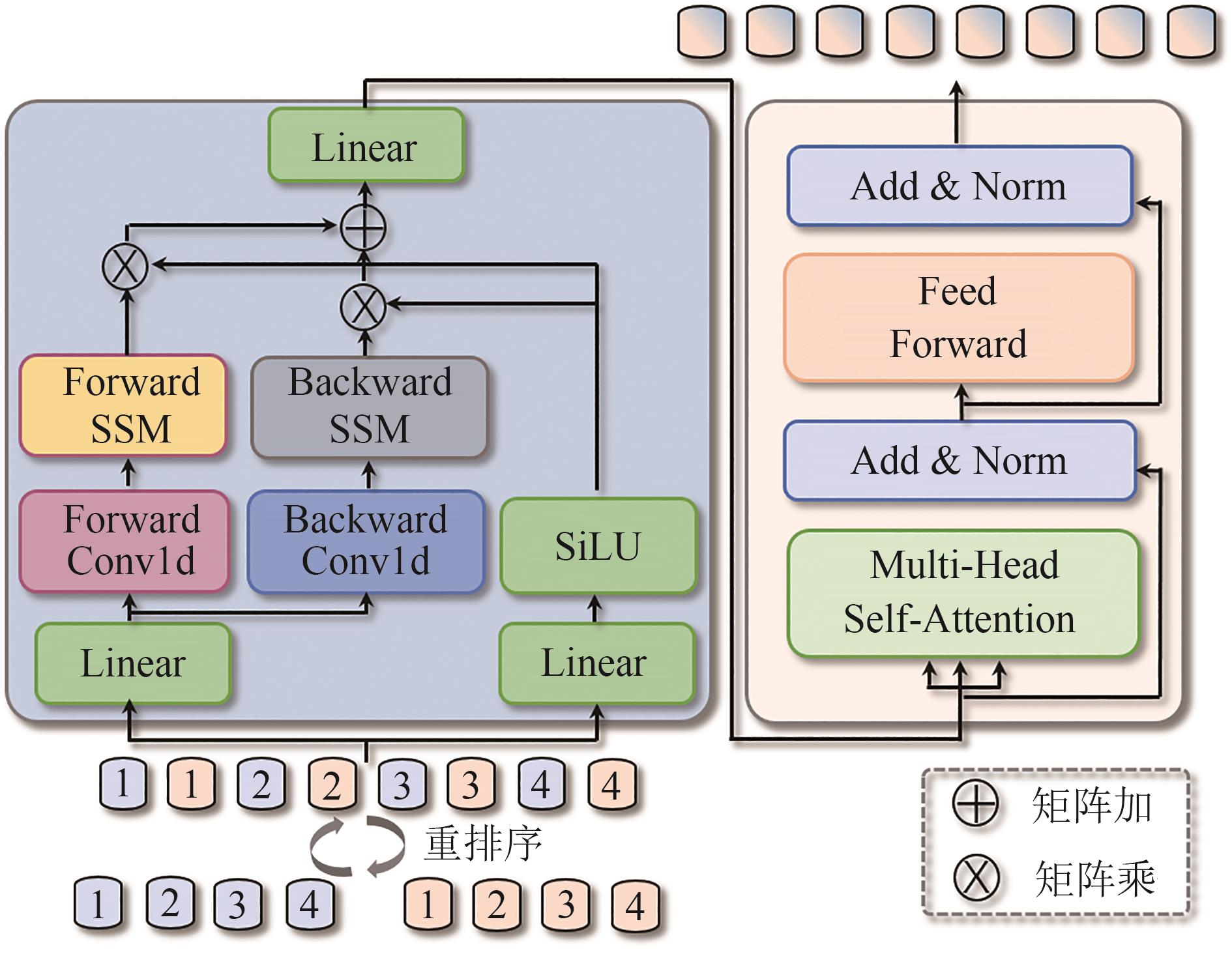
图 2 空间增强的SSM和Transformer模块Fig. 2. Spatially enhanced state space model and Transformer module (SH-ST)![]() 图 3 时间增强的SSM和Transformer模块Fig. 3. Temporally enhanced state space model and Transformer module (TH-ST)
图 3 时间增强的SSM和Transformer模块Fig. 3. Temporally enhanced state space model and Transformer module (TH-ST)2.1 理论基础
本节我们介绍一类具有线性复杂度的SSM,特别是S4[34]和Mamba[35]。它们受到线性时不变(linear time-invariant, LTI)连续系统的启发,通过隐状态
h(t)∈RN 将输入序列x(t)∈R 映射为输出y(t)∈R 。该系统通过矩阵A∈RN×N 控制隐状态的动态变化,矩阵B∈RN×1 和C∈R1×N 分别作为投影参数,数学方式表示如下:S4[34]和Mamba[35]被构建为这些连续系统的离散化等价模型,将输入序列
{x1,x2,…,xk} 映射为输出{y1,y2,…,yk} ,采用零阶保持(zero-order hold, ZOH)离散化方法,将连续参数(A,B) 转换为离散形式(ˉA,ˉB) 。该转换引入时间尺度参数Δ∈RD 实现,具体定义如下:经过离散化之后,线性系统在每个离散时间步
k 的行为可描述为:Mamba[35]引入选择性状态空间机制,突破了SSM的LTI限制。该机制允许矩阵
ˉA ,ˉB 和Δ 随输入序列变化,从而提升序列间的选择性信息处理,使模型具备上下文感知能力。2.2 时空增强的状态空间模型和Transformer
如图1所示,我们展示了所提出的时空增强的状态空间模型和Transformer(ST2)的整体架构。ST2由四部分组成,视觉编码器,空间增强的SSM和Transformer模块(SH-ST),时间增强的SSM和Transformer模块(TH-ST)以及解码器。依据前人研究[17],我们使用经过图像与文本对齐的CLIP视觉编码器作为主干,提取视频特征并标记化为
Fin∈RL×D 。L 和D 分别表示视频帧数量和标记维度。特征向量首先添加位置嵌入,然后依次输入SH-ST和TH-ST,通过SH-ST和TH-ST的相互协调作用,增强模型的时空联合建模能力,随后经过投影层,最后获得时空增强后的特征。特征与句子嵌入一并送入解码器中,生成视频文本描述并计算损失,该部分详细内容我们将在2.5节详细讨论。则ST2的视频处理数据流如下公式所示:其中
F 表示中间视觉特征,ΨPos 表示可学习位置嵌入,Γ(,) 表示重排序,ΨProj 表示投影层,ΨSH-ST 和ΨTH-ST 分别表示SH-ST和TH-ST模块。2.3 空间增强的SSM和Transformer模块
如图2所示,我们的空间增强的SSM和Transformer模块(SH-ST)由并行的SSM和Transformer构成。标准的Mamba是处理一维序列的,其因果扫描机制使其不适用于视觉任务中的空间感知理解。受到文献[36]的启发,我们在展平的视频特征上进行前向SSM和后向SSM扫描,实现双向建模,从而增强模型对视频特征的理解。
定义输入SH-ST模块
ΨSH-ST 中的特征为Fpos ,则SH-ST中的SSM处理流程可以表述为:其中
σ(⋅) 表示SiLU激活函数,Ψconv1d 和Ψlinear 分别表示一维卷积和线性变换,flip(⋅) 表示对序列进行顺序反转。进一步地,我们考虑异构模型对视频理解可能存在帮助,我们利用Transformer块进一步挖掘视频中的信息:其中,
FFN(⋅) 表示前馈神经网络,norm(⋅) 表示归一化,Transformer的关键组件是缩放点积注意力机制,即Att(⋅) ,表示如下:其中,
i∈[1,NH] ,NH 表示注意力头数量,*i∈RL*×dk(*∈{Q,K,V}) ,L* 表示采样的帧序列长度,dk=dh/Nh ,dh 表示预定义的模型维度,bi∈RLK 表示基于头部的偏置项,Q 、K 、V 由FPos 线性映射而来。2.4 时间增强的SSM和Transformer模块
SH-ST通过融合SSM的异构模块增强模型的空间变化感知能力,我们还提出了时间增强的SSM和Transformer模块(TH-ST),以促进时间建模,如图3所示。考虑到SH-ST增强后的特征
FSSM∈ RL×D 、FTrans∈RL×D 是异构模型对相同视频帧序列的不同表达,为了促进二者在时间上信息交互,我们摒弃常用的拼接,采用重排序Γ(,) 操作。具体地,我们将FSSM∈RL×D 、FTrans∈RL×D 以交叉的方式重排序,构建序列Fre=[F(0)SSM,F(0)Trans,F(1)SSM, F(1)Trans,…, F(2L)SSM,F(2L)Trans]∈R2L×D 。然后序列Fre 将会串行输入到TH-ST中的SSM和Transformer中,如公式(8)~(15)所述。不同于SH-ST模块中SSM和Transformer间并行操作,我们认为此种串行的方式有助于增强模型对重排序后特征的时间信息增强。另外我们共享了SH-ST和TH-ST模块中的SSM权重,减少参数量的同时,增强SH-ST和TH-ST模块间信息共享,提升ST2模型的时空联合建模能力。需要注意的是,最后TH-ST输出的特征序列增加了两倍,因此,我们在最后增加了投影层,剔除冗余信息、提升模型效率,如公式(7)所示。2.5 解码器和损失函数
将视频文本对表示为
(𝒱,𝒮) ,随机采样一个视频样本为v∈𝒱 ,v={v1,v2,…,vL} ,L 为预定义的帧数目,取v 的一条对应的文本描述作为标签(Ground Truth, GT)记为s∈𝒮 ,s={s1,s2,…,sz} ,z 表示句子长度。视频v 经过编码生成特征FST2 后,解码器阶段旨在生成文本描述s ,每一个词sz 基于特征FST2 和先前生成的词s:z-1 。具体地,在第z 个时间步,我们计算输入的嵌入向量ez∈Rdh :其中下标
[i] 表示矩阵的第i 行,Wword∈R|υ|×dh 和Wpos∈RTmax×dh 分别表示词和位置嵌入可训练矩阵,|υ| 表示字典大小,Tmax 表示预定义的最长序列长度。随后,我们将E≤z={e1,e2,…,ez} 和FST2 送入到字幕解码器中,产生隐状态hw∈Rdh :字幕解码器由
Ndec 个Transformer块构成[11],其核心缩放点积注意力机制如公式(15)所示。最后我们将hw 送入分类头预测下一个词sz :其中
p(sz|s:z-1,FST2)∈R|υ| 表示基于字典υ 的分布,Wcls∈Rdh×|υ| 表示可学习矩阵。将视频特征FST2 和给定的GT字幕s 作为输入,计算输出与GT的交叉熵损失ℒ :其中
θ 表示可学习参数。3. 实验设置
3.1 数据集
我们在两个广泛使用的数据集MSVD[37],MSR-VTT[38]上进行了实验。其中MSVD包含1970个视频,每个视频片段有40个字幕,每个视频片段的平均持续时间约为10 s。参考文献[17][19],包括使用1200个视频进行训练,100个视频进行验证,670个视频进行测试。MSR-VTT是一个通用的视频字幕数据集,包括10000个视频片段,每个片段都注释有20个字幕。平均每个视频剪辑持续约15 s。我们遵循官方[38]的划分方式,使用6153个片段进行训练,497个片段用于验证,2090个片段用于测试。
3.2 指标
为了将我们的方法与其他的方法对比,文章采用了如下四个指标,BLEU@4[39](B@4)是基于精度的指标,METEOR[40](M)计算句子级别的分数,ROUGE[41](R)使用最长公共子序列来计算句子之间的相似度,CIDEr[42](C)是一种基于共识的指标。
3.3 特征
每个视频均匀采样固定帧训练推理,即预定义的帧数目
L=20 ,采样不足20帧时用零填充。我们采用12层块尺寸为32的ViT-B/32[11]作为我们的视频编码器(缩写为CLIPViT-B/32)提取特征,具体地,我们使用预训练的CLIPViT-B/32[13]作为基干,以提取丰富的特征。预训练的CLIPViT-B/32对于视频字幕任务在文献[17-19]中证明是有效的。3.4 模型设置
我们SH-ST和TH-ST中采用的Transformer的隐藏层维度
dh 为768,注意力头Nh 为12,Mamba中一维卷积核大小为4,隐藏层维度为768。在获得增强的时空视觉特征后,特征输入到隐藏层维度为768,Transformer 块为Ndec=2 层的解码器中,为每个视频生成字幕。我们在所有注意力、Mamba和其他层上使用0.1的dropout概率。3.5 其他细节
我们设置最大单词数目
Tmax 为48,最长帧数目L 为20,字典大小|υ| 为30522。训练时,批大小(batch size)为32,使用ADAM[16]训练共30 epochs,对于偏置、归一化的偏置和权重不设置权重衰减,其他参数L2权重衰减系数设置为0.01。学习率初始化为7e-6,预热比例为0.1,在预热期内,学习率线性增加,之后线性衰减为0。在评估/推理时,设置集数搜索的大小为5。4. 对比实验
为了评估ST2的性能,我们在MSVD,MSR-VTT上进行了实验。我们对比了如下三类最先进的方法:(1)基于检测的:STG-KD[25],ORG-TRL[26],LSRT[27],E-TGM [28]和TTA[29];(2)检索增强的:OpenBook[22],R-ConvED[23]和CARE[19]; (3)无检索和检测的:SGN[43],HRNAT[44],RSFD[45],CLIP4Caption[17]和VEIN[46]。我们用IRN-V2,RN和3D-RNX分别表示INCEPTION-RESNET-V2[47],RESNET[48]和3D RESNEXT[34]。
1) MSVD: 如表1所示,我们的方法在所有指标上超越了其他方法,包括其他使用CLIP特征提取的方法,如CARE、VEIN。值得注意的是,除了我们的方法和CLIP4Caption没有提取额外信息,其他方法引入一种或多种额外信息,如运动矢量、检测、检索等。尽管如此,我们的方法也在所有指标上超越了这些方法,其原因是我们的模型设计无须额外信息即避免了引入噪声,另一方面我们对视觉时空信息的充分挖掘和增强起到了作用。
表 1 MSVD数据集对比实验结果Tab. 1. Comparison of experimental results on the MSVD datasetMethod Year Feature Detection Retrieval MSVD Extractor Motion C B@4 M R STG-KD 2020 R101 I3D Object - 93 52.2 36.9 73.9 ORG-TRL 2020 IRv2 3D-RX Object - 95.2 54.3 36.4 73.9 LSRT 2022 IRv2 I3D Object - 98.5 55.6 37.1 73.5 E-TGM 2019 IRv2 C3D Topic - 83 79.3 33.9 71 TTA 2021 R152 3D-RX Concept - 87.7 51.8 35.5 72.4 R-ConvED 2022 IRv2 - - √ 83.4 50.5 34.4 - SGN 2021 R101 3D-RX - - 94.3 52.8 35.5 72.9 HRNAT 2022 IRv2 I3D - - 98.1 55.7 36.8 74.1 RSFD 2023 R101 3D-RX - - 96.7 51.2 35.7 72.9 CARE 2023 CLIPViT-B/32 3D-RX Concept √ 106.9 56.3 39.1 75.6 VEIN 2024 CLIPViT-B/32 3D-RX - - 98.9 55.7 37.6 74.4 CLIP4Caption† 2021 CLIPViT-B/32 - - - 104.9 56.3 38.7 75.9 Ours - CLIPViT-B/32 - - - 111.8 57.6 39.8 76.8 2) MSR-VTT:如表2所示,本文方法在三个指标上超越了最先进的方法,虽然在指标B@4上略低CARE模型,但也取得了较好的结果。可能的原因是CARE利用了多种模态信息,提高了概念先验的准确性,而B@4是关注精度的指标,因此CARE在该指标方面具有优势。
表 2 MSR-VTT数据集对比实验结果Tab. 2. Comparison of experimental results on the MSR-VTT datasetMethod Year Feature Detection Retrieval MSR-VTT Extractor Motion Audio C B@4 M R STG-KD 2020 RN-101 I3D - Object - 47.1 40.5 28.3 60.9 ORG-TRL 2020 IRN-v2 3D-RNX - Object - 50.9 43.6 28.8 62.1 LSRT 2022 IRN-v2 I3D - Object - 49.5 42.6 28.3 61 E-TGM 2019 IRN-v2 C3D √ Topic - 51.8 44.9 29.6 62.8 TTA 2021 RN-152 3D-RNX - Concept - 46.7 41.4 27.7 61.1 OpenBook 2021 IRN-v2 3D-RNX - - √ 52.3 43.1 29 61.9 R-ConvED 2022 IRN-v2 - - - √ 48.3 37.8 27.6 - SGN 2021 RN-101 3D-RNX - - - 49.5 40.8 28.3 60.8 HRNAT 2022 IRN-v2 I3D - - - 48.2 42.1 28 61.6 RSFD 2023 RN-101 3D-RNX - - - 53.1 43.4 29.3 62.3 CARE 2023 CLIPViT-B/32 3D-RNX √ Concept √ 59.7 48.7 31.5 65.2 VEIN 2024 CLIPViT-B/32 3D-RNX - - - 55.3 44.1 30 62.6 CLIP4Caption 2021 CLIPViT-B/32 - - - - 57.7 46.1 30.7 63.7 Ours - CLIPViT-B/32 - - - - 60.3 48.1 31.6 65.2 5. 消融实验
为说明设计的空间增强的SSM和Transformer模块(SH-ST)以及时间增强的SSM和Transformer模块(TH-ST),我们对其构成进行了消融实验,如表3所示。其中,TH-ST表示不采用重排序操作,直接对特征进行拼接,TH-STR表示采用重排序操作。由表3可知,随着我们增加设计的SH-ST和TH-ST,相比于基线效果变好。然而,当我们不采用重排序时(Exp.3),效果不如仅使用SH-ST,可能的原因是由于采用拼接操作对于增强时间信息提取无益,甚至可能产生不良影响。当添加重排序时(Exp.4),即ST2模型时,效果达到最佳,说明我们的ST2模型设计增强了时空表达能力,有效提取视频中的信息,从而生成更加准确的文本描述。
表 3 MSVD数据集消融实验结果Tab. 3. Results of ablation experiment on the MSVD datasetExp. SH-ST TH-ST TH-STR MSVD C B@4 M R 1(baseline) 104.9 56.3 38.7 75.9 2 √ 111.1 57.4 39.6 76.6 3 √ √ 109.6 57.1 39.3 76.5 4(ours) √ √ 111.8 57.6 39.8 76.8 近期有多种的SSM,我们对其进行了实验,如文献[36]中的ViM块,文献[49]中的DBM块,并最终确定采用ViM为本文中状态空间模型的基本块,结果如表4所示。DBM效果相对不佳的原因可能是,该模块设计用于视频特征提取。然而本文模型采用主流的方案,即先用预训练的CLIP提取视频帧特征,随后送入视觉编码器中,这可能是导致DBM效果相对不佳的原因。
表 4 选择不同SSM在MSVD数据集上的性能对比Tab. 4. Comparison of the performance of different SSMs on the MSVD datasetExp. DBM ViM MSVD C B@4 M R 1 √ 109.3 57.6 39.7 76.1 2(ours) √ 111.8 57.6 39.8 76.8 6. 定性结果
如图4所示,分别展示了MSVD和MSR-VTT数据集上4个字幕示例,我们比较了提出的方法ST2和基线方法,其中基线方法采用CLIP4Caption,即仅使用Transformer架构。预测错误和正确的关键词用红色和绿色标记。本文方法和基线方法(CLIP4Caption)采用预训练的CLIP模型提取视频帧特征,而CLIP是在大规模的图像文本对上训练而成的,导致在提取视频特征时,可能出现时间特征提取不充分,时空联合建模的不足等问题。在CLIP4Caption中,采用一层Transformer视频编码器对提取的视频帧进行增强,但过于简单的视频编码器可能导致视频帧特征增强不足,因而生成部分错误的视频字幕。
![]() 图 4 MSVD和MSR-VTT数据集主观实验对比Fig. 4. Comparison of subjective experiments on MSVD and MSR-VTT dataset
图 4 MSVD和MSR-VTT数据集主观实验对比Fig. 4. Comparison of subjective experiments on MSVD and MSR-VTT dataset从图中可观察到ST2的两个优势:(1)我们的方法生成的文本描述相比于基线方法更符合视频内容,实体描述更准确,这可能得益于我们设计的空间增强的SSM和Transformer模块(SH-ST)。例如,ST2精确描述出了(a)中的“小提琴(violin)”,(b)中的“鸡蛋(eggs)”,(e)中的“海绵宝宝和章鱼哥(spongebob and squidward)”。(2)ST2产生更少的错误方面表现得更好,且动作描述更加准确。基线将(c)中的“摔倒在路上(falling on the street)”识别为了“推动汽车(pushing a car)”,将(d)中的“切叶子(cutting leaves)”识别为了“切青洋葱(chopping green onions)”,将(g)中“3d游戏场景”识别为了“骑马(riding a horse)”,而ST2识别并产生了正确的动作描述,如(c)中“摔倒在路上(falling on the road)”,(d)中“切树叶(cutting green leaves)”,(g)中“玩游戏(game is being played)”,进一步说明我们的时空增强的状态空间模型和Transformer模型设计发挥了积极作用。
7. 结论
为了充分增强视觉特征提取,弥补先前模型对视频特征的时空联合建模的不足,以改善字幕识别的准确性,我们提出ST2模型增强时空特征的提取,并引入了在长序列建模具有潜力的Mamba模型。具体地,我们提出时间增强模块TH-ST和空间增强模块SH-ST,二者分别为异构Mamba和Transformer的串并行结构,分别增强时间和空间信息表示。另外,在TH-ST中,我们将SH-ST的输出进行重排序,以促进TH-ST的时间建模。最后,TH-ST和SH-ST模块之间状态空间模型权重共享,这不仅减少了模型的参数量,还增强了模块间的信息共享,提升了模型对视觉特征的时空联合建模能力。实验结果表示,我们的方法ST2超越了大部分对比方法,且消融实验证明了我们所提模块的有效性,为Mamba在实际应用中提供一定的思路。未来将通过高效注意力、优化视觉潜在空间等[50-52]方式进一步改善特征表示空间及其质量,同时探索更多与新颖的状态空间模型融合方案。
-
![]()
图 2 空间增强的SSM和Transformer模块
Figure 2. Spatially enhanced state space model and Transformer module (SH-ST)
![]()
图 3 时间增强的SSM和Transformer模块
Figure 3. Temporally enhanced state space model and Transformer module (TH-ST)
![]()
图 4 MSVD和MSR-VTT数据集主观实验对比
Figure 4. Comparison of subjective experiments on MSVD and MSR-VTT dataset
表 1 MSVD数据集对比实验结果
Table 1 Comparison of experimental results on the MSVD dataset
Method Year Feature Detection Retrieval MSVD Extractor Motion C B@4 M R STG-KD 2020 R101 I3D Object - 93 52.2 36.9 73.9 ORG-TRL 2020 IRv2 3D-RX Object - 95.2 54.3 36.4 73.9 LSRT 2022 IRv2 I3D Object - 98.5 55.6 37.1 73.5 E-TGM 2019 IRv2 C3D Topic - 83 79.3 33.9 71 TTA 2021 R152 3D-RX Concept - 87.7 51.8 35.5 72.4 R-ConvED 2022 IRv2 - - √ 83.4 50.5 34.4 - SGN 2021 R101 3D-RX - - 94.3 52.8 35.5 72.9 HRNAT 2022 IRv2 I3D - - 98.1 55.7 36.8 74.1 RSFD 2023 R101 3D-RX - - 96.7 51.2 35.7 72.9 CARE 2023 CLIPViT-B/32 3D-RX Concept √ 106.9 56.3 39.1 75.6 VEIN 2024 CLIPViT-B/32 3D-RX - - 98.9 55.7 37.6 74.4 CLIP4Caption† 2021 CLIPViT-B/32 - - - 104.9 56.3 38.7 75.9 Ours - CLIPViT-B/32 - - - 111.8 57.6 39.8 76.8  下载: 导出CSV
下载: 导出CSV
表 2 MSR-VTT数据集对比实验结果
Table 2 Comparison of experimental results on the MSR-VTT dataset
Method Year Feature Detection Retrieval MSR-VTT Extractor Motion Audio C B@4 M R STG-KD 2020 RN-101 I3D - Object - 47.1 40.5 28.3 60.9 ORG-TRL 2020 IRN-v2 3D-RNX - Object - 50.9 43.6 28.8 62.1 LSRT 2022 IRN-v2 I3D - Object - 49.5 42.6 28.3 61 E-TGM 2019 IRN-v2 C3D √ Topic - 51.8 44.9 29.6 62.8 TTA 2021 RN-152 3D-RNX - Concept - 46.7 41.4 27.7 61.1 OpenBook 2021 IRN-v2 3D-RNX - - √ 52.3 43.1 29 61.9 R-ConvED 2022 IRN-v2 - - - √ 48.3 37.8 27.6 - SGN 2021 RN-101 3D-RNX - - - 49.5 40.8 28.3 60.8 HRNAT 2022 IRN-v2 I3D - - - 48.2 42.1 28 61.6 RSFD 2023 RN-101 3D-RNX - - - 53.1 43.4 29.3 62.3 CARE 2023 CLIPViT-B/32 3D-RNX √ Concept √ 59.7 48.7 31.5 65.2 VEIN 2024 CLIPViT-B/32 3D-RNX - - - 55.3 44.1 30 62.6 CLIP4Caption 2021 CLIPViT-B/32 - - - - 57.7 46.1 30.7 63.7 Ours - CLIPViT-B/32 - - - - 60.3 48.1 31.6 65.2
下载: 导出CSV
表 3 MSVD数据集消融实验结果
Table 3 Results of ablation experiment on the MSVD dataset
Exp. SH-ST TH-ST TH-STR MSVD C B@4 M R 1(baseline) 104.9 56.3 38.7 75.9 2 √ 111.1 57.4 39.6 76.6 3 √ √ 109.6 57.1 39.3 76.5 4(ours) √ √ 111.8 57.6 39.8 76.8
下载: 导出CSV
表 4 选择不同SSM在MSVD数据集上的性能对比
Table 4 Comparison of the performance of different SSMs on the MSVD dataset
Exp. DBM ViM MSVD C B@4 M R 1 √ 109.3 57.6 39.7 76.1 2(ours) √ 111.8 57.6 39.8 76.8
下载: 导出CSV
-
[1] GUADARRAMA S,KRISHNAMOORTHY N,MALK- ARNENKAR G,et al. YouTube2Text:Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition[C]// 2013 IEEE International Conference on Computer Vision. Sydney,NSW,Australia. IEEE,2013:2712- 2719. doi:10.1109/iccv.2013.337 doi: 10.1109/iccv.2013.337
[2] ROHRBACH M,QIU Wei,TITOV I,et al. Translating video content to natural language descriptions[C]// 2013 IEEE International Conference on Computer Vision. Sydney,NSW,Australia. IEEE,2013:433- 440. doi:10.1109/iccv.2013.61 doi: 10.1109/iccv.2013.61
[3] XU Ran,XIONG Caiming,CHEN Wei,et al. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework[C]. Proceedings of the AAAI Conference on Artificial Intelligence,2015,29(1):2346- 2352. doi:10.1609/aaai.v29i1.9512 doi: 10.1609/aaai.v29i1.9512
[4] HOCHREITER S,SCHMIDHUBER J. Long short-term memory[J]. Neural Computation,1997,9(8):1735- 1780. doi:10.1162/neco.1997.9.8.1735 doi: 10.1162/neco.1997.9.8.1735
[5] VENUGOPALAN S,ROHRBACH M,DONAHUE J,et al. Sequence to sequence—video to text[C]// 2015 IEEE International Conference on Computer Vision(ICCV). Santiago,Chile. IEEE,2015:4534- 4542. doi:10.1109/iccv.2015.515 doi: 10.1109/iccv.2015.515
[6] BALLAS N,YAO Li,PAL C,et al. Delving deeper into convolutional networks for learning video representations[EB/OL]. 2015:1511. 06432. https://arxiv.org/abs/1511.06432v4.
[7] PAN Pingbo,XU Zhongwen,YANG Yi,et al. Hierarchical recurrent neural encoder for video representation with application to captioning[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Las Vegas,NV,USA. IEEE,2016:1029- 1038. doi:10.1109/cvpr.2016.117 doi: 10.1109/cvpr.2016.117
[8] YAO Li,TORABI A,CHO K,et al. Describing videos by exploiting temporal structure[C]// 2015 IEEE International Conference on Computer Vision(ICCV). Santiago,Chile. IEEE,2015:4507- 4515. doi:10.1109/iccv.2015.512 doi: 10.1109/iccv.2015.512
[9] YU Haonan,WANG Jiang,HUANG Zhiheng,et al. Video paragraph captioning using hierarchical recurrent neural networks[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Las Vegas,NV,USA. IEEE,2016:4584- 4593. doi:10.1109/cvpr.2016.496 doi: 10.1109/cvpr.2016.496
[10] WANG Junbo,WANG Wei,HUANG Yan,et al. Hierarchical memory modelling for video captioning[C]// Proceedings of the 26th ACM International Conference on Multimedia. Seoul Republic of Korea. ACM,2018:63- 71. doi:10.1145/3240508.3240538 doi: 10.1145/3240508.3240538
[11] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An image is worth 16 x 16 words:Transformers for image recognition at scale[EB/OL]. 2010:arXiv:2010. 11929. https://arxiv.org/pdf/2010.11929.
[12] LUO Huaishao,JI Lei,SHI Botian,et al. UniVL:A unified video and language pre-training model for multimodal understanding and generation[EB/OL]. 2020:2002. 06353. https://arxiv.org/abs/2002.06353v3.
[13] ZHU Linchao,YANG Yi. ActBERT:Learning global-local video-text representations[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Seattle,WA,USA. IEEE,2020:8743- 8752. doi:10.1109/cvpr42600.2020.00877 doi: 10.1109/cvpr42600.2020.00877
[14] KORBAR B,PETRONI F,GIRDHAR R,et al. Video understanding as machine translation[EB/OL]. 2020:2006. 07203. https://arxiv.org/abs/2006.07203v2. doi:10.1007/1-4020-4653-7_3 doi: 10.1007/1-4020-4653-7_3
[15] LIN K,LI Linjie,LIN C C,et al. SwinBERT:End-to-end transformers with sparse attention for video captioning[C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). New Orleans,LA,USA. IEEE,2022:17928- 17937. doi:10.1109/cvpr52688.2022.01742 doi: 10.1109/cvpr52688.2022.01742
[16] RADFORD A,KIM J,HALLACY C,et al. Learning transferable visual models from natural language supervision[C]// 2021 International Conference Machine Learning,Online. PMLR,2021:8748- 8763.
[17] TANG Mingkang,WANG Zhanyu,LIU Zhenhua,et al. CLIP4Caption:CLIP for video caption[C]// Proceedings of the 29th ACM International Conference on Multimedia. Virtual Event China. ACM,2021:4858- 4862. doi:10.1145/3474085.3479207 doi: 10.1145/3474085.3479207
[18] YANG Bang,ZHANG Tong,ZOU Yuexian. CLIP meets video captioning:Concept-aware representation learning does matter[C]// Pattern Recognition and Computer Vision. Cham:Springer International Publishing,2022:368- 381. doi:10.1007/978-3-031-18907-4_29 doi: 10.1007/978-3-031-18907-4_29
[19] YANG Bang,CAO Meng,ZOU Yuexian. Concept-aware video captioning:Describing videos with effective prior information[J]. IEEE Transactions on Image Processing,2023,32:5366- 5378. doi:10.1109/tip.2023.3307969 doi: 10.1109/tip.2023.3307969
[20] WU Bofeng,LIU Buyu,HUANG Peng,et al. Concept parser with multimodal graph learning for video captioning[J]. IEEE Transactions on Circuits and Systems for Video Technology,2023,33(9):4484- 4495. doi:10.1109/tcsvt.2023.3277827 doi: 10.1109/tcsvt.2023.3277827
[21] XU Jilan,HUANG Yifei,HOU Junlin,et al. Retrieval-augmented egocentric video captioning[C]// 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Seattle,WA,USA. IEEE,2024:13525- 13536. doi:10.1109/cvpr52733.2024.01284 doi: 10.1109/cvpr52733.2024.01284
[22] ZHANG Ziqi,QI Zhongang,YUAN Chunfeng,et al. Open-book video captioning with retrieve-copy-generate network[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,TN,USA. IEEE,2021:9832- 9841. doi:10.1109/cvpr46437.2021.00971 doi: 10.1109/cvpr46437.2021.00971
[23] CHEN Jingwen,PAN Yingwei,LI Yehao,et al. Retrieval augmented convolutional encoder-decoder networks for video captioning[J]. ACM Transactions on Multimedia Computing,Communications,and Applications,2023,19(1 s):1- 24. doi:10.1145/3539225 doi: 10.1145/3539225
[24] ZENG Yawen,WANG Yiru,LIAO Dongliang,et al. Contrastive topic-enhanced network for video captioning[J]. Expert Systems with Applications,2024,237:121601. doi:10.1016/j.eswa.2023.121601 doi: 10.1016/j.eswa.2023.121601
[25] PAN Boxiao,CAI Haoye,HUANG Dean,et al. Spatio-temporal graph for video captioning with knowledge distillation[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Seattle,WA,USA. IEEE,2020:10867- 10876. doi:10.1109/cvpr42600.2020.01088 doi: 10.1109/cvpr42600.2020.01088
[26] ZHANG Ziqi,SHI Yaya,YUAN Chunfeng,et al. Object relational graph with teacher-recommended learning for video captioning[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Seattle,WA,USA. IEEE,2020:13275- 13285. doi:10.1109/cvpr42600.2020.01329 doi: 10.1109/cvpr42600.2020.01329
[27] LI Liang,GAO Xingyu,DENG Jincan,et al. Long short-term relation transformer with global gating for video captioning[J]. IEEE Transactions on Image Processing,2022,31:2726- 2738. doi:10.1109/tip.2022.3158546 doi: 10.1109/tip.2022.3158546
[28] CHEN Shizhe,JIN Qin,CHEN Jia,et al. Generating video descriptions with latent topic guidance[J]. IEEE Transactions on Multimedia,2019,21(9):2407- 2418. doi:10.1109/tmm.2019.2896515 doi: 10.1109/tmm.2019.2896515
[29] TU Yunbin,ZHOU Chang,GUO Junjun,et al. Enhancing the alignment between target words and corresponding frames for video captioning[J]. Pattern Recognition,2021,111:107702. doi:10.1016/j.patcog.2020.107702 doi: 10.1016/j.patcog.2020.107702
[30] SHEN Yaojie,GU Xin,XU Kai,et al. Accurate and fast compressed video captioning[C]// 2023 IEEE/CVF International Conference on Computer Vision(ICCV). Paris,France. IEEE,2023:15512- 15521. doi:10.1109/iccv51070.2023.01426 doi: 10.1109/iccv51070.2023.01426
[31] HARA K,KATAOKA H,SATOH Y. Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and ImageNet?[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT,USA. IEEE,2018:6546- 6555. doi:10.1109/cvpr.2018.00685 doi: 10.1109/cvpr.2018.00685
[32] 武文博,顾广华,刘青茹,等. 基于深度卷积与全局特征的图像密集字幕描述[J]. 信号处理,2020,36(9):1525- 1532. WU Wenbo,GU Guanghua,LIU Qingru,et al. Dense image caption with deep convolution and global visual[J]. Journal of Signal Processing,2020,36(9):1525- 1532.(in Chinese)
[33] 程照辉,毋立芳,刘健. 基于运动特征的视频检索[J]. 信号处理,2011,27(5):765- 770. CHENG Zhaohui,WU Lifang,LIU Jian. Motion feature based video retrieval[J]. Journal of Signal Processing,2011,27(5):765- 770.(in Chinese)
[34] GU A,GOEL K,RÉ C. Efficiently modeling long sequences with structured state spaces[EB/OL]. 2021:2111. 00396. https://arxiv.org/abs/2111.00396v3.
[35] GU A,DAO T. Mamba:Linear-time sequence modeling with selective state spaces[EB/OL]. 2023:2312. 00752. https://arxiv.org/abs/2312.00752v2.
[36] ZHU Lianghui,LIAO Bencheng,ZHANG Qian,et al. Vision mamba:Efficient visual representation learning with bidirectional state space model[EB/OL]. 2024:2401. 09417. https://arxiv.org/abs/2401.09417v2.
[37] CHEN D,DOLAN W. Collecting highly parallel data for paraphrase evaluation[C]// 2011 Association for Computational Linguistics,Portland,OR. ACL,2011:190- 200.
[38] XU Jun,MEI Tao,YAO Ting,et al. MSR-VTT:A large video description dataset for bridging video and language[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Las Vegas,NV,USA. IEEE,2016:5288- 5296. doi:10.1109/cvpr.2016.571 doi: 10.1109/cvpr.2016.571
[39] PAPINENI K,ROUKOS S,WARD T,et al. BLEU:A method for automatic evaluation of machine translation[J]. Proceedings of the Annual Meeting of the Association for Computational Linguistics,2002:311- 318. doi:10.3115/1073083.1073135 doi: 10.3115/1073083.1073135
[40] LAVIE A,AGARWAL A. Meteor:An automatic metric for MT evaluation with high levels of correlation with human judgments[C]// Proceedings of the Second Workshop on Statistical Machine Translation- StatMT'07. Prague,Czech Republic. Morristown,NJ,USA:Association for Computational Linguistics,2007:65- 72. doi:10.3115/1626355.1626389 doi: 10.3115/1626355.1626389
[41] LIN C Y. Rouge:A package for automatic evaluation of summaries[C]// 2004 Association for Computational Linguistics,Barcelona,Spain. ACM,2004:74- 81. doi:10.3115/1218955.1219032 doi: 10.3115/1218955.1219032
[42] VEDANTAM R,ZITNICK C L,PARIKH D. CIDEr:Consensus-based image description evaluation[C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Boston,MA,USA. IEEE,2015:4566- 4575. doi:10.1109/cvpr.2015.7299087 doi: 10.1109/cvpr.2015.7299087
[43] RYU H,KANG S,KANG H,et al. Semantic grouping network for video captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2021,35(3):2514- 2522. doi:10.1609/aaai.v35i3.16353 doi: 10.1609/aaai.v35i3.16353
[44] GAO Lianli,LEI Yu,ZENG Pengpeng,et al. Hierarchical representation network with auxiliary tasks for video captioning and video question answering[J]. IEEE Transactions on Image Processing,2022,31:202- 215. doi:10.1109/tip.2021.3120867 doi: 10.1109/tip.2021.3120867
[45] ZHONG Xian,LI Zipeng,CHEN Shuqin,et al. Refined semantic enhancement towards frequency diffusion for video captioning[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2023,37(3):3724- 3732. doi:10.1609/aaai.v37i3.25484 doi: 10.1609/aaai.v37i3.25484
[46] SONG Peipei,GUO Dan,YANG Xun,et al. Emotional video captioning with vision-based emotion interpretation network[J]. IEEE Transactions on Image Processing,2024,33:1122- 1135. doi:10.1109/tip.2024.3359045 doi: 10.1109/tip.2024.3359045
[47] SZEGEDY C,IOFFE S,VANHOUCKE V,et al. Inception-v4,inception-ResNet and the impact of residual connections on learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2017,31(1):4278- 4284. doi:10.1609/aaai.v31i1.11231 doi: 10.1609/aaai.v31i1.11231
[48] HE Kaiming,ZHANG Xiangyu,REN Shaoqing,et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Las Vegas,NV,USA. IEEE,2016:770- 778. doi:10.1109/cvpr.2016.90 doi: 10.1109/cvpr.2016.90
[49] CHEN Guo,HUANG Yifei,XU Jilan,et al. Video mamba suite:State space model as a versatile alternative for video understanding[EB/OL]. 2024:2403. 09626. https://arxiv.org/abs/arxiv.2403.09626.
[50] LI Zechao,SUN Yanpeng,ZHANG Liyan,et al. CTNet:Context-based tandem network for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,44:9904- 9917. doi:10.1109/tpami.2021.3132068 doi: 10.1109/tpami.2021.3132068
[51] LI Zechao,TANG Jinhui,MEI Tao. Deep collaborative embedding for social image understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,41(9):2070- 2083. doi:10.1109/tpami.2018.2852750 doi: 10.1109/tpami.2018.2852750
[52] CHUN S. Improved probabilistic image-text representations[EB/OL]. 2023:2305. 18171. https://arxiv.org/abs/2305.18171v5.

计量
- 文章访问数: 54
- HTML全文浏览量: 1
- PDF下载量: 25
